
在开源周的第三天,DeepSeek 推出了一个名为 DeepGEMM 的新库,专为高效、简洁的 FP8 通用矩阵乘法(GEMM)而设计。这一工具旨在解决现代 AI 计算中矩阵乘法的效率和精度问题,特别是在需要高效推理和低功耗的场景下。
DeepGEMM 的核心优势
1. 高效的 FP8 矩阵乘法
DeepGEMM 通过结合 FP8 算术和细粒度缩放技术,显著降低了计算和内存开销。它采用了双层累积策略(提升技术),在不牺牲性能的情况下最大限度地减少计算误差。这种设计使得 DeepGEMM 在处理 FP8 张量核心时表现出色,尤其适合 NVIDIA Hopper 张量核心。
2. 灵活的部署与即时编译
DeepGEMM 使用 CUDA 编写,并通过轻量级即时(JIT)模块在运行时编译所有内核。这意味着在安装过程中无需冗长的编译过程,从而简化了集成步骤。JIT 编译策略允许动态优化内核参数,根据特定的 GEMM 形状和硬件配置进行定制。
3. 针对现代硬件的优化
DeepGEMM 专为 NVIDIA Hopper 张量核心定制,充分利用了现代 GPU 架构的优势。它支持普通和混合专家(MoE)分组 GEMM,适应了现代推理和训练任务的实际需求。此外,DeepGEMM 的设计简洁,核心代码量少,便于学习和优化。
4. 性能提升与实际应用
在 NVIDIA H800 GPU 上的测试表明,DeepGEMM 在各种矩阵维度上实现了显著的性能提升。例如,普通 GEMM 操作的加速因子在 1.4 到 2.7 倍之间,而 MoE 模型的分组 GEMM 也显示出 1.1 到 1.2 倍的加速。这些性能提升得益于 DeepGEMM 的动态优化策略和对 Hopper 张量内存加速器(TMA)的优化使用。
技术细节与设计亮点
细粒度缩放与双层累积
DeepGEMM 的核心是采用细粒度缩放与 FP8 算术相结合,以平衡速度和数值精度。为了解决 FP8 张量核心累积的问题,该库使用通过 CUDA 核心的双层累积策略。这种方法在不牺牲性能的情况下最大限度地减少了计算过程中的错误。
简洁的代码设计
DeepGEMM 的实现非常简洁,单个核心内核函数大约包含 300 行代码。这种简洁性不仅有助于理解基本原理,而且便于社区进一步改进。与 CUTLASS 和 CuTe 等现有库相比,DeepGEMM 避免了复杂模板或代数框架的依赖,专注于优化普通和分组配置的 GEMM 操作。
支持 MoE 模型的分组 GEMM
DeepGEMM 提供了针对 MoE 模型的分组 GEMM 支持,包括连续布局和掩码布局。每种布局都经过精心设计,以适应每个专家的不同令牌计数,满足现代推理和训练任务的实际需求。
性能表现与实际测试
DeepGEMM 的性能数据清晰地展示了其效率改进。在 NVIDIA H800 GPU 上的测试表明,DeepGEMM 在各种矩阵维度上实现了显著的加速。例如:
- 普通 GEMM 操作:加速因子在 1.4 到 2.7 倍之间。
- MoE 模型的分组 GEMM:连续布局和掩码布局均显示出 1.1 到 1.2 倍的加速。
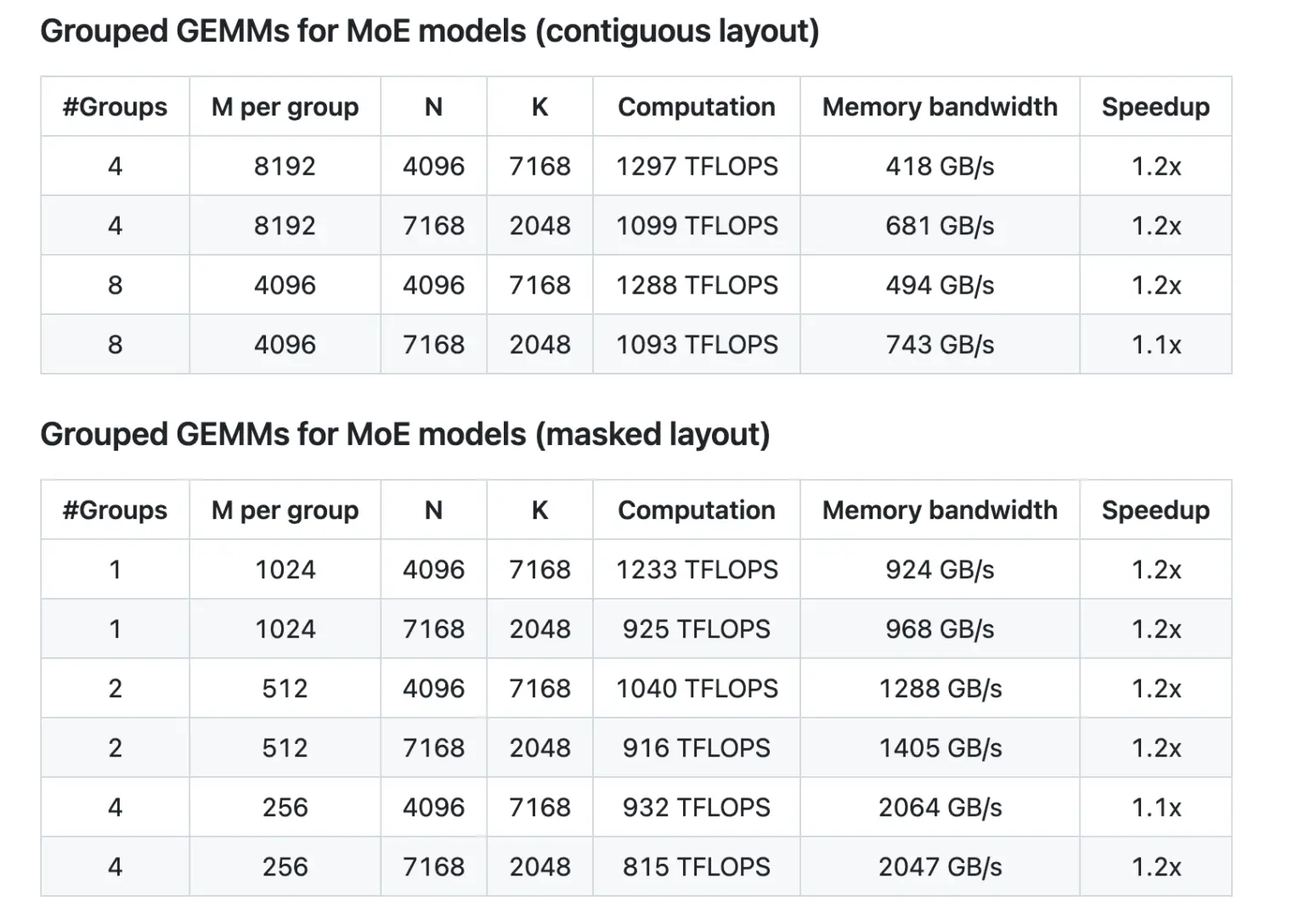
这些性能提升得益于 DeepGEMM 的动态优化策略和对 Hopper 张量内存加速器(TMA)的优化使用。此外,DeepGEMM 提供了多个实用程序函数,帮助开发人员对齐张量维度并配置共享内存,确保库可以顺利集成到更大的系统中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











