
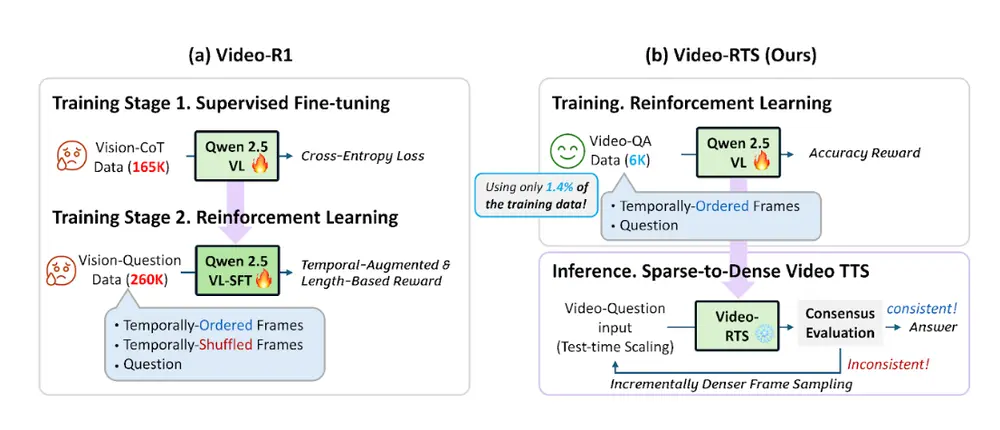
北卡罗来纳大学教堂山分校的研究人员提出了一种全新的视频推理方法——Video-RTS(Reinforcement Learning with Test-time Scaling),旨在解决当前视频理解模型中普遍存在的高数据成本、训练复杂度高以及推理效率低等问题。
该方法结合了高效的强化学习训练机制与自适应测试时缩放策略,在显著降低训练样本需求的同时,提升了模型在多个视频推理任务上的表现。
为什么需要 Video-RTS?
当前主流的视频推理模型通常依赖于以下两种资源密集型操作:
- 大规模监督微调(SFT):需要大量带有思维链(Chain-of-Thought, CoT)注释的视频数据。
- 长文本生成与复杂推理流程:模型必须处理冗长的中间推理过程,导致训练和推理成本居高不下。
而 Video-RTS 则跳过了这些繁琐步骤,采用一种“轻量训练 + 动态推理”的方式,在保证性能的前提下大幅提升效率。
核心功能一览
- ✅ 高效训练:仅需少量标注数据(如6K视频问答对),即可达到甚至超越传统方法(如使用169K样本的Video-R1)的性能。
- ✅ 动态稀疏到密集推理:根据输出一致性自动调整帧采样密度,实现更高效的计算资源分配。
- ✅ 降低计算开销:通过纯强化学习训练和测试时扩展策略,减少训练与推理阶段的整体资源消耗。
技术亮点解析
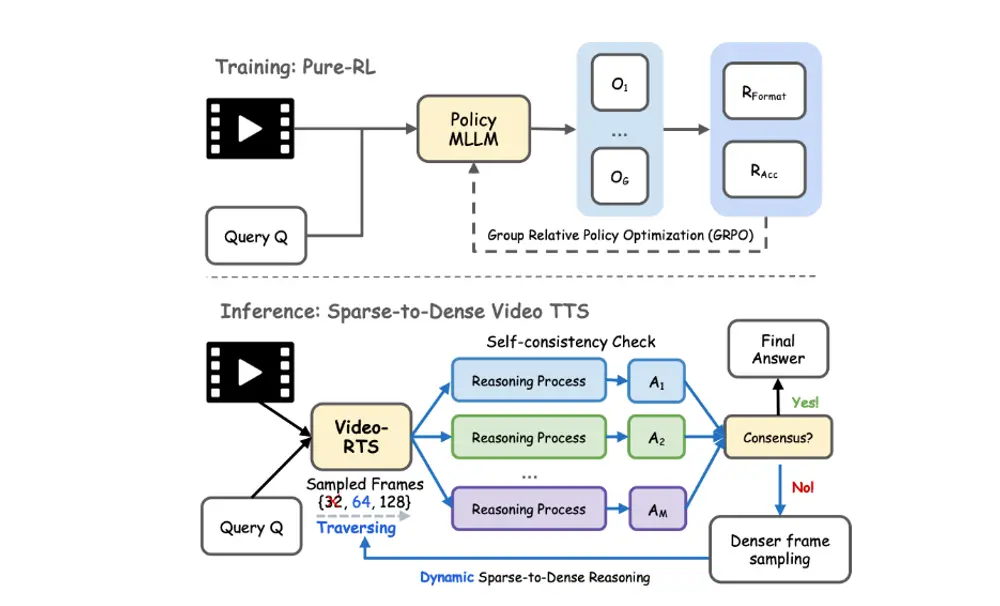
1. 纯强化学习训练(RL-only Training)
Video-RTS 使用 Group Relative Policy Optimization (GRPO) 算法进行训练,直接优化最终输出结果,而非依赖复杂的 CoT 注释。训练过程中利用两类奖励函数:
- 格式奖励(Rformat):确保输出符合预期格式(如推理依据+答案)。
- 准确性奖励(Racc):鼓励模型生成正确答案。
这种方式使得训练流程更加简洁,同时保持了高质量的推理能力。
2. 自适应测试时缩放(Adaptive Test-Time Scaling)
传统的视频推理模型往往采用固定帧采样策略,导致在简单问题上浪费计算资源,或在复杂问题上遗漏关键信息。
Video-RTS 提出了一种从稀疏到密集的动态推理机制:
- 初始阶段使用少量帧进行推理。
- 若输出不一致,则逐步增加帧数,直到结果稳定或达到最大帧数限制。
- 使用**多数投票机制(majority voting)**判断是否需要进一步细化推理。
这种策略不仅提高了推理准确率,也显著减少了不必要的计算开销。
实验评估结果
Video-RTS 在多个主流视频推理基准上进行了验证,均表现出色:
| 基准名称 | 相较于现有模型的提升 |
|---|---|
| Video-Holmes | ↑4.2% 准确率 |
| MMVU | ↑2.6% 准确率 |
此外:
- 数据效率方面:仅使用6K训练样本,表现优于使用169K样本的Video-R1。
- 推理效率方面:平均使用约42.8帧完成推理,远低于传统方法所需帧数。
工作流程简述
训练阶段:
- 使用 GRPO 强化学习算法进行训练。
- 输入为视频 + 问题 + 答案对。
- 输出由 Rformat 和 Racc 奖励函数共同优化。
推理阶段:
- 模型初始使用稀疏帧进行推理。
- 若输出不一致,逐步增加帧采样密度。
- 通过 majority voting 决定最终答案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











