
由 AI2(Allen Institute for AI) 推出的 FlexOlmo,正在重新定义语言模型的训练方式。
它提出了一种名为“数据协作”的新范式,让多个数据拥有者在不共享原始数据的前提下,共同参与模型训练,并保有对其数据使用的控制权和归因机制。
这不仅解决了当前语言模型开发中的关键瓶颈——数据获取问题,也为医疗、政府、金融等对数据隐私高度敏感的行业打开了新的 AI 合作窗口。
为什么我们需要数据协作?
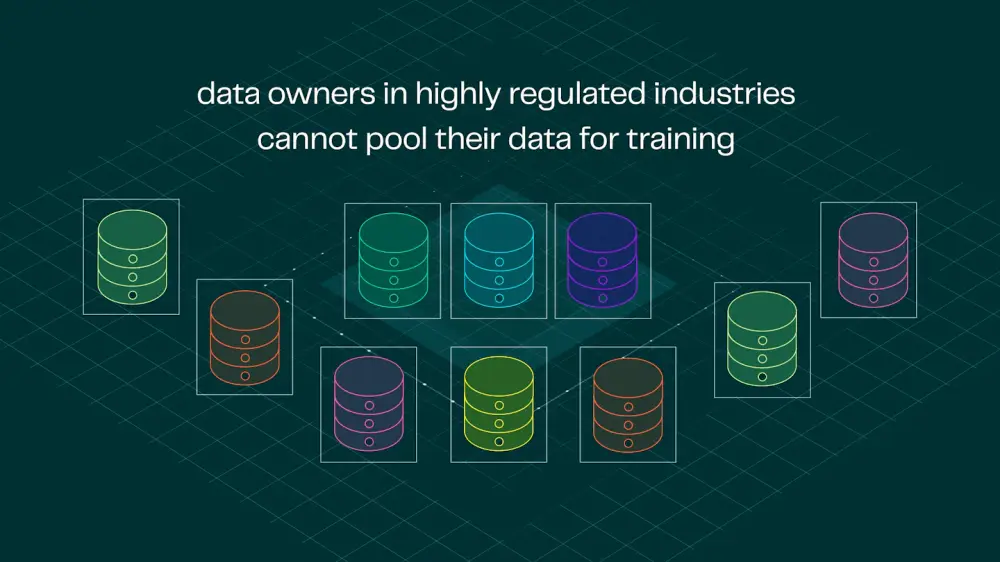
训练一个强大、泛化能力出色的语言模型,离不开高质量、多样化的数据支持。但现实是:
- 数据所有者往往不愿或无法共享原始数据
因为一旦数据被公开,就失去了控制权,也无法获得应有的归因。 - 传统训练流程缺乏灵活性
数据需要一次性整合进集中数据集,不可逆、不能撤回。 - 价值流失严重
数据是资产,但在现有模式下,数据贡献者几乎得不到任何回报。
FlexOlmo 正是为了打破这些限制而诞生的。
FlexOlmo 的核心机制
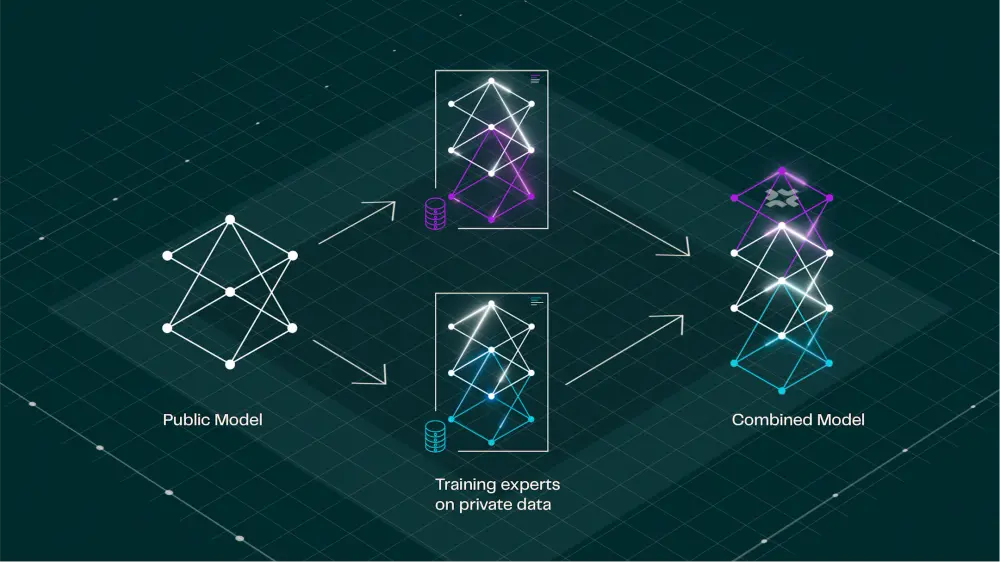
FlexOlmo 的理念非常独特:
每个数据拥有者都可以从公共模型中本地分支,基于自己的私有数据训练一个“专家模块”,再将该模块贡献回共享模型中。
这意味着:
- 数据无需上传或共享
- 数据拥有者可随时决定是否停用自己贡献的模块
- 在推理阶段,数据使用情况可被追踪并归因
这种机制使得多方可以在保护数据隐私的前提下,协同构建一个统一、强大的语言模型。
技术架构解析
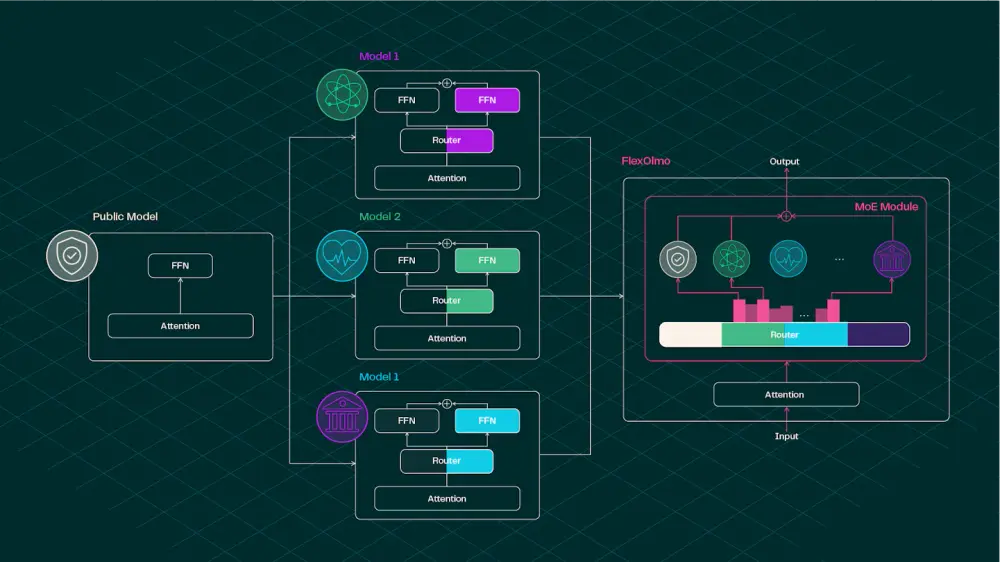
FlexOlmo 基于 混合专家(MoE, Mixture of Experts)架构 设计,每个专家模块独立训练于私有数据之上,最终集成到统一模型中。
关键创新点包括:
- 异步分布式训练:各组织可各自训练专家模块,互不干扰。
- 冻结锚定模型:确保不同专家之间具备一致性,能协同工作。
- 无联合训练需求:专家模块训练过程中不需要共享数据或同步训练过程。
- 动态路由机制:通过文档嵌入初始化的领域信息嵌入,实现灵活的专家调用。
这一设计不仅提升了训练效率,也极大增强了模型的适应性与安全性。
实验验证与性能表现
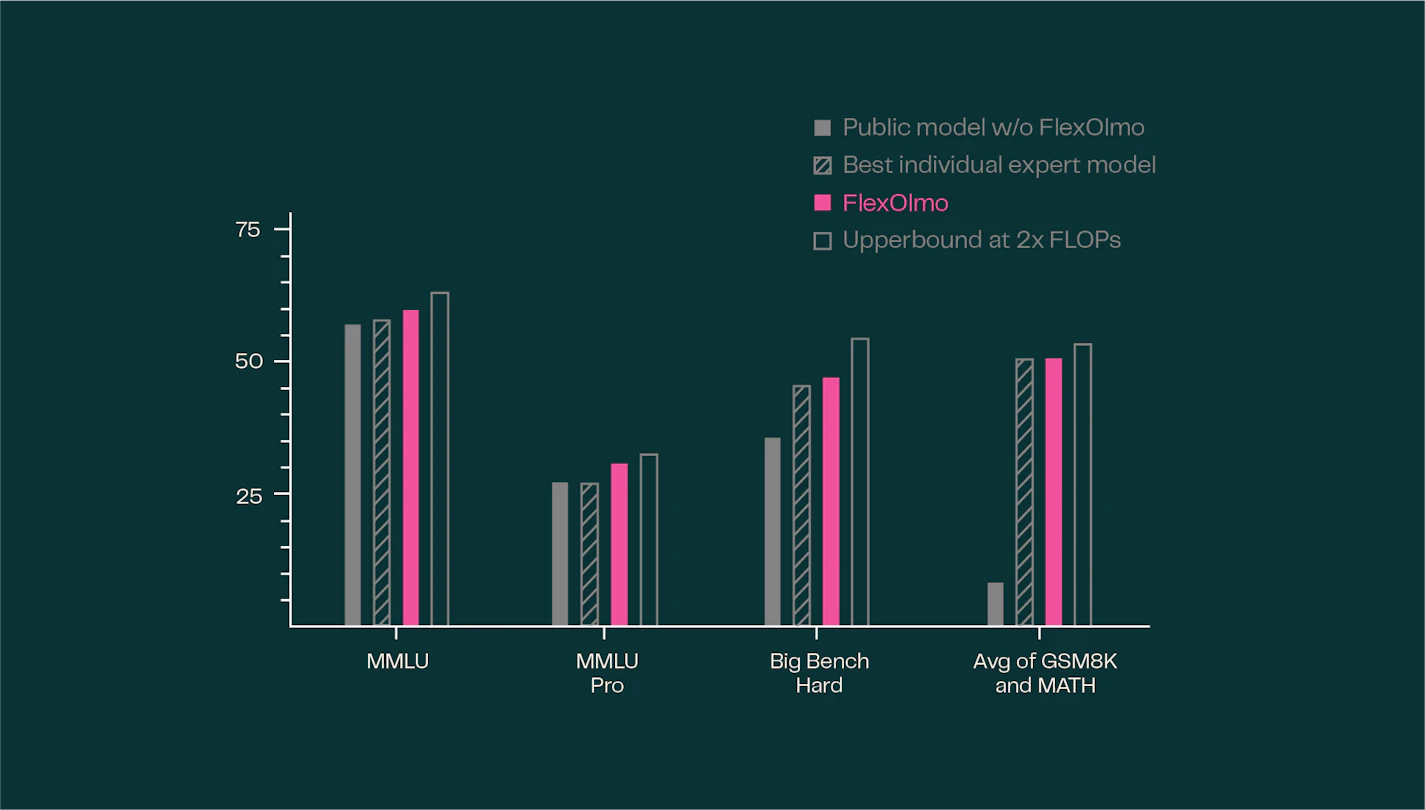
研究人员通过实验验证了 FlexOlmo 的有效性:
- 使用私有数据训练的专家模块加入后,模型性能显著优于原版公共模型。
- 新模型保留了各专家模块的专业能力,并融合了更多数据多样性。
- FlexOlmo 的整体性能接近于理想状态下的“全数据训练”模型。
此外,研究团队还测试了数据泄露风险:
- 针对训练数据提取攻击的实验证明,从 FlexOlmo 中恢复原始数据的概率极低(仅约 0.7%)。
- 如果仍有顾虑,数据贡献者可以选择使用 差分隐私(Differential Privacy) 训练专家模块,进一步提升安全性。
应用场景广泛
FlexOlmo 特别适用于那些拥有高质量但受限数据的机构:
- 医疗领域:医院可以利用患者数据训练 AI 模型,而不必共享病人信息。
- 政府与公共部门:处理涉及国家安全或公民隐私的数据时更加安全可控。
- 金融服务:银行、保险等机构可在不暴露客户数据的情况下参与 AI 联合建模。
- 学术界:跨院校合作时既能保护知识产权,又能实现知识共享。
总结:FlexOlmo 带来的变革
| 优势 | 描述 |
|---|---|
| 数据隐私保护 | 不共享原始数据,避免泄露风险 |
| 灵活控制权 | 可随时停用模块,掌控使用时间 |
| 归因透明 | 数据贡献者在推理阶段获得明确归因 |
| 高效协作 | 异步训练 + MoE 架构,大幅提升扩展性 |
| 安全可靠 | 支持差分隐私,防止数据反推 |
FlexOlmo 打开了一个新的 AI 开发模式:以数据为中心的协作式训练。它不仅推动了开放模型的发展,也让数据拥有者能够真正参与到 AI 生态中来,而无需牺牲自身利益。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











