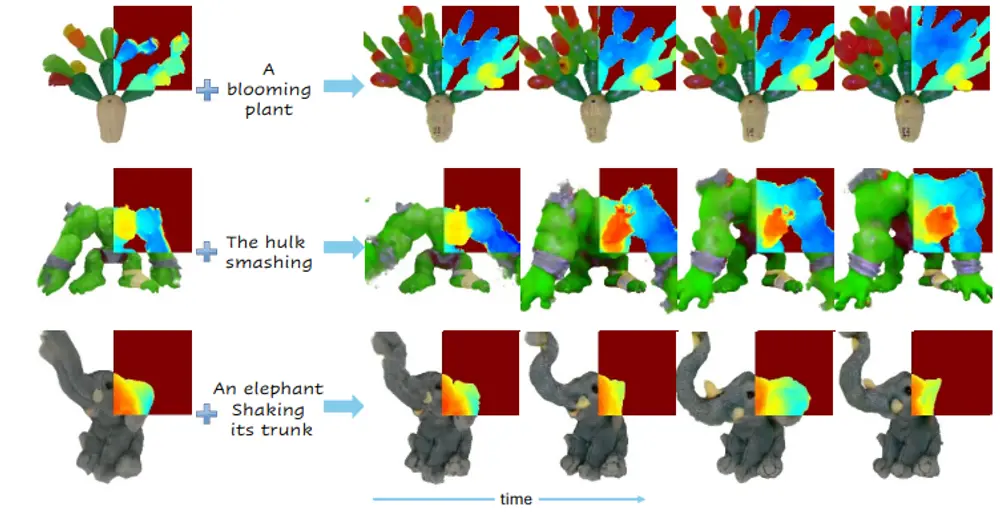
由新加坡国立大学、浙江大学、罗切斯特理工学院、南京大学、中国科学技术大学、曼苏里大学人工智能学院、上海人工智能实验室和SII联合提出的新方法 LoongX,首次将多模态脑机接口(BCI)信号引入扩散模型中,实现无需手动输入、无需文本提示的图像编辑系统,为运动能力受限或语言障碍用户提供了一种全新的交互方式。
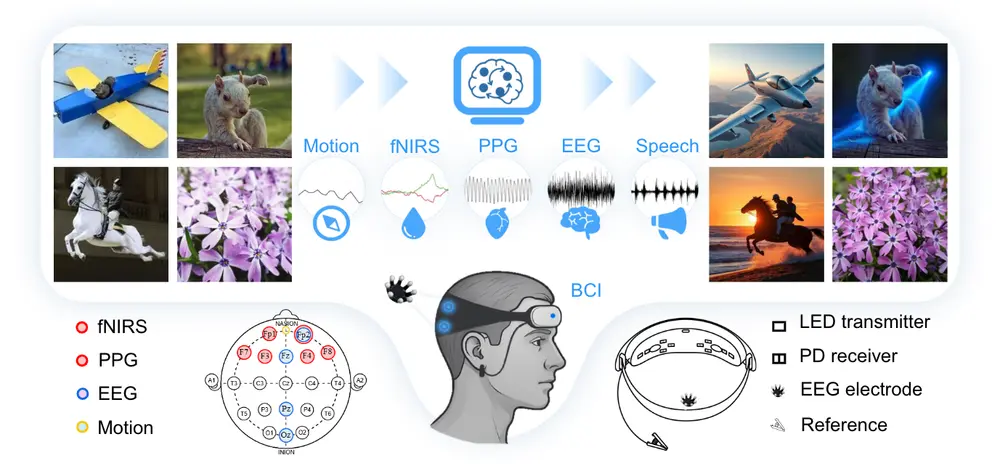
该方法通过一个跨尺度状态空间编码器(CS3) 和一个动态门控融合模块(DGF),有效整合来自L-Mind数据集的多种神经生理信号(如EEG、fNIRS、PPG等),并将其映射到语义嵌入空间中,最终驱动图像生成模型完成意图一致的编辑操作。
研究背景与动机
传统图像编辑高度依赖鼠标、键盘或文本指令,这对部分用户群体(如肢体障碍者、语言障碍者)构成了使用门槛。近年来,脑机接口(BCI) 技术的发展为“无接触式”人机交互提供了可能,但现有方法大多依赖单一模态信号(如EEG或fMRI),难以准确捕捉复杂的用户意图。
LoongX 的提出正是为了解决这一问题:
- 利用多模态神经生理信号(EEG、fNIRS、PPG、头部运动)
- 实现无手操作、无语言输入的图像编辑
- 推动更直观、更具包容性的交互方式发展
核心贡献
- 提出LoongX框架:首个结合多模态神经信号与扩散模型进行图像编辑的系统
- 构建L-Mind数据集:包含23,928对图像编辑样本及同步记录的EEG、fNIRS、PPG、语音和运动信号
- 设计CS3与DGF模块:
- CS3:跨尺度状态空间编码器,提取多模态信号的多层次特征
- DGF:动态门控融合模块,将多模态特征聚合到统一潜在空间,并与语义对齐
- 验证神经信号与语言指令的互补性:实验表明,神经信号与语音结合的编辑效果优于纯文本提示
主要功能与特点
✅ 无接触式图像编辑
- 用户仅需想象图像编辑任务,无需任何物理操作或语言输入
- 系统通过脑电、血氧、心率等信号识别用户的视觉意图
✅ 多模态信号融合
- 同时采集并融合 EEG、fNIRS、PPG 和头部运动信号
- 更全面地反映大脑认知状态与视觉注意力
✅ 语义对齐机制
- 使用对比学习预训练编码器,将神经信号映射到 CLIP 嵌入空间
- 微调阶段进一步提升编辑结果与用户意图的一致性
✅ 高效的扩散模型集成
- 将对齐后的神经信号作为条件输入,驱动 DiT 模型生成目标图像
- 支持精细控制,如颜色调整、对象增删、布局重构等
工作流程概述
- 数据采集
使用轻量级无线 BCI 设备同步采集用户在构思图像编辑任务时的 EEG、fNIRS、PPG、头部运动和语音信号。 - 特征提取
通过 CS3 编码器从各模态信号中提取多尺度特征,捕捉时间序列中的关键信息。 - 特征融合与对齐
使用 DGF 模块将多模态特征聚合至统一潜在空间,并通过微调使其与 CLIP 文本嵌入对齐。 - 扩散模型驱动编辑
将对齐后的神经特征作为条件输入,引导扩散模型(DiT)生成符合用户意图的编辑图像。 - 预训练与微调策略
在大规模认知数据集上预训练编码器,再在 L-Mind 数据集上进行端到端微调,提升模型泛化能力。
实验结果与分析
| 指标 | LoongX | OmniControl |
|---|---|---|
| CLIP-I | 0.6605 | 0.6558 |
| DINO | 0.4812 | 0.4636 |
- 仅使用神经信号的编辑性能已接近文本驱动基线水平,表明其具有强大的语义理解能力。
- 结合神经信号与语音指令后,在 CLIP-T 指标上表现更优(0.2588 vs 0.2549),说明神经信号能有效补充语言信息,提高语义一致性。
多模态信号贡献分析
- EEG:主导视觉感知任务,尤其在图像重构与细节控制中表现突出;
- fNIRS:增强特征鲁棒性,有助于保持图像结构保真度;
- PPG 与 头部运动:辅助识别用户注意力与情绪状态,提升整体交互体验。
应用前景与意义
LoongX 的成功实践展示了多模态神经信号在图像编辑中的巨大潜力,标志着从“语言驱动”迈向“意图驱动”的重要一步。
它不仅为残障人士提供了一种全新的交互方式,也为未来更自然、更直觉的人机交互系统提供了技术基础。随着脑机接口设备的便携化与普及,LoongX 所代表的“意念编辑”模式有望广泛应用于创意设计、医疗康复、虚拟现实等多个领域。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











