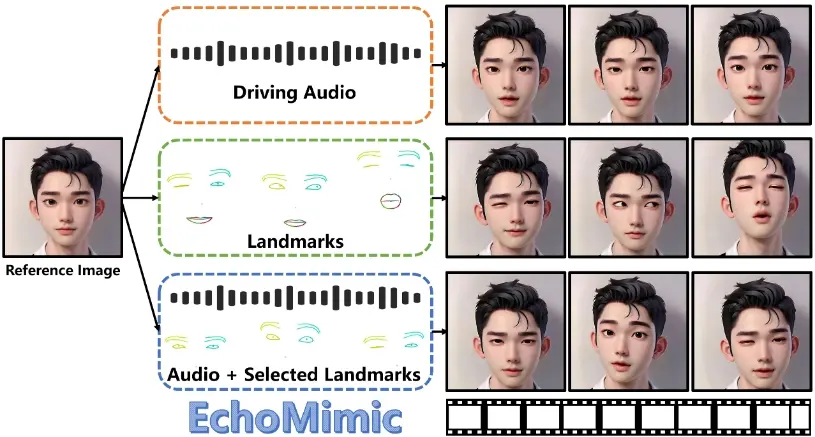
蚂蚁集团支付宝终端技术部推出肖像动画新技术EchoMimic,它可以将静态的肖像照片转化为逼真的动态视频。EchoMimic创新性地结合音频与面部标志点进行联合训练,并通过一项新颖的训练策略,使其不仅能分别依据音频或面部标志点生成肖像视频,还能够巧妙融合两者,实现更加细腻和真实的动画效果。例如,你给定一张人像照片和一段音频,EchoMimic就能够根据音频中的声音和语调,让照片中的人看起来像是在说话或表达情感。
- 项目主页:https://badtobest.github.io/echomimic.html
- GitHub:https://github.com/BadToBest/EchoMimic
- 模型地址:https://huggingface.co/BadToBest/EchoMimic
- WebUi 版本:https://github.com/greengerong/EchoMimic
主要功能:
- EchoMimic可以单独使用音频或面部关键点(如眼睛、嘴巴的位置)来生成动态视频。
- 它还能够结合音频和选定的面部关键点来生成更加逼真和可控的动态视频。
主要特点:
- EchoMimic采用了一种新颖的训练策略,能够同时利用音频和面部关键点进行训练。
- 它在多个公共数据集上进行了广泛的比较,展示了在定量和定性评估中的优越性能。
- 该技术提供了可视化效果和源代码的访问,使得研究者和开发者可以更好地理解和应用这项技术。
工作原理:
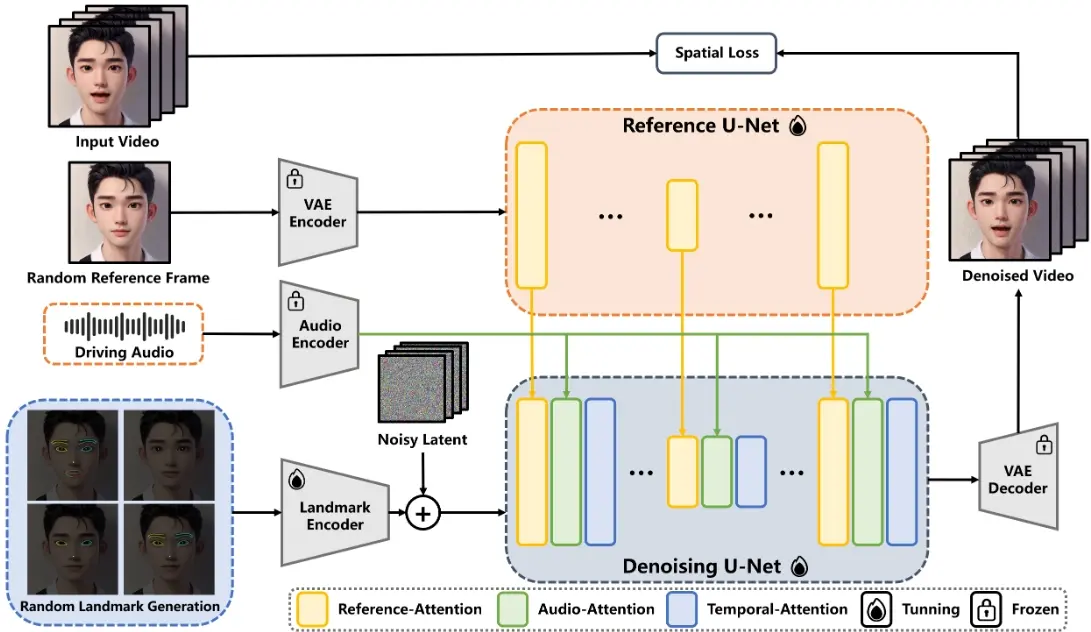
- EchoMimic基于一种称为“扩散模型”的生成模型,这种模型通过在大量图像数据集上进行训练,能够生成高度逼真的图像。
- 它使用变分自编码器(VAE)将原始图像转换为潜在空间的表示,然后通过逐步去除注入的噪声并利用文本指令来重建图像。
- EchoMimic框架中包含几个专门的模块,包括用于编码参考图像的Reference U-Net、用于引导网络使用面部关键点的Landmark Encoder,以及用于编码音频输入的Audio Encoder。
具体应用场景:
- 游戏和娱乐产业:为虚拟角色生成逼真的面部动画和表情,提升玩家的沉浸感。
- 媒体制作:在电影或视频制作中,可以用于生成角色的对话和表情,减少实际拍摄的需要。
- 教育和培训:创建教育内容,如虚拟教师或讲解者,提供更加生动的互动体验。
- 社交媒体和内容创作:用户可以利用自己的照片和声音,快速生成个性化的动态内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











