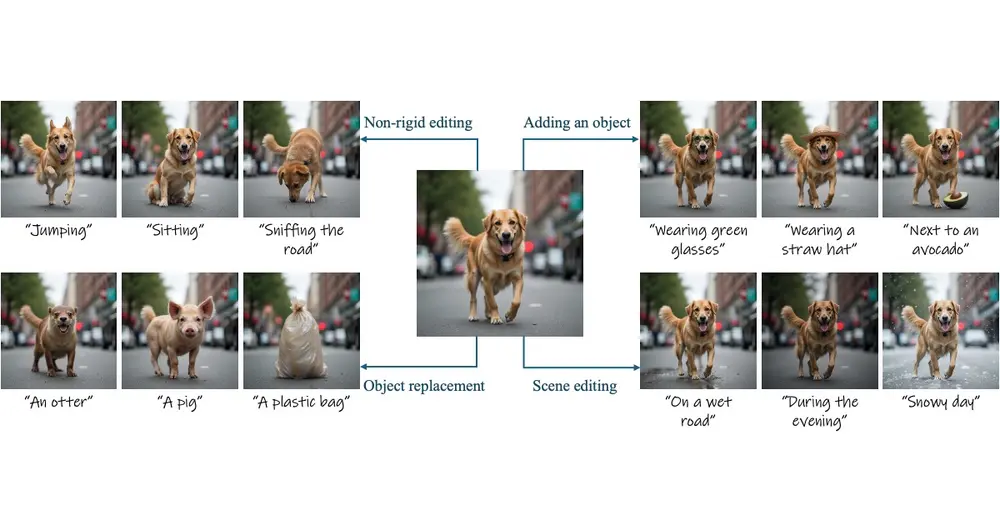
卡内基梅隆大学和赖希曼大学的研究人员推出创新框架Generative Photomontage,它使用户能够通过组合多个生成的图像来创建他们所需的图像,这个过程就像是用不同的图像拼贴出一幅全新的画面。例如,你想要创造一个未来风格的机器人,但是你在一次生成的图像中只喜欢机器人的头部,在另一次生成中只喜欢机器人的身体。使用Generative Photomontage,你可以选择两个图像中你喜欢的部分,然后这个框架会帮你将这两部分融合在一起,创造出一个既包含你喜欢的头部又包含你喜欢的身体的机器人图像。
- 项目主页:https://lseancs.github.io/generativephotomontage
- GitHub:https://github.com/lseancs/GenerativePhotomontage
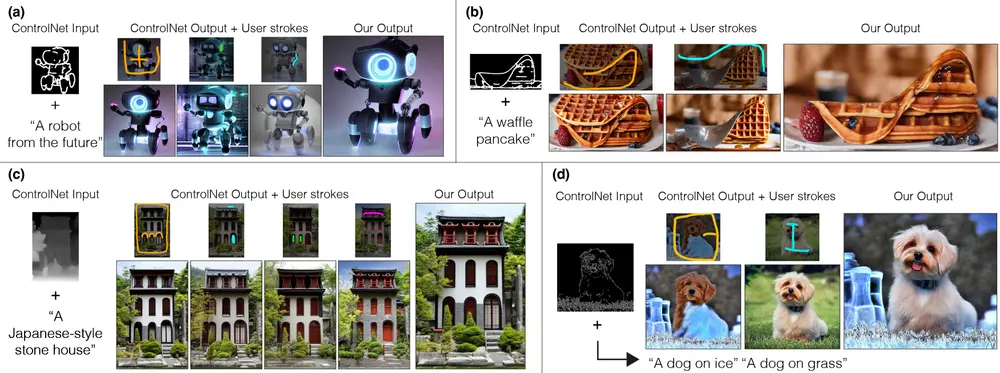
主要功能和特点:
- 用户控制:用户可以通过简单的笔触界面选择生成结果中他们喜欢的部分。
- 图像融合:该方法使用一种新颖的技术,通过在扩散特征空间中进行基于图的优化来分割图像,并使用一种新的特新空间融合方法来组合选定的区域。
- 保留真实感:在融合过程中,该方法能够忠实地保留用户选定的区域,同时和谐地将它们融合在一起。
- 多种应用:该框架可以用于多种应用,包括生成新的外观组合、修正形状错误和移除图像中的人工制品,以及改善文本提示的对齐。
工作原理:
- 用户首先使用ControlNet生成一系列图像,这些图像使用相同的输入条件和不同的种子。
- 用户通过画笔工具在图像上选择他们喜欢的区域。
- 系统接受用户的笔触作为输入,利用扩散特征空间中的图优化技术来分割图像。
- 然后,系统在最终去噪过程中通过一种新的特征注入和混合方法来组合这些分割后的区域。

具体应用场景:
- 创意设计:用户可以探索和混合不同的建筑元素来形成新的建筑设计。
- 艺术创作:用户可以结合不同的颜色和纹理来创造独特的艺术作品。
- 图像编辑:用户可以修正由ControlNet生成的图像中的错误形状或人工制品。
- 文本到图像的生成:用户可以通过组合简短的提示来创建与复杂文本提示对齐的图像。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











