
近年来,大语言模型(LLM)的快速发展为AI领域带来了巨大的潜力,但其对计算资源的高需求也限制了广泛应用。无论是研究机构还是个人开发者,都面临着高昂的成本和技术门槛。然而,这一局面可能即将被打破。
由Yandex Research与麻省理工学院(MIT)、阿卜杜拉国王科技大学(KAUST)和奥地利科学技术研究所(ISTA)联合开发的HIGGS方法,提供了一种全新的解决方案。这种创新的压缩技术无需高性能硬件或额外数据,即可快速将大语言模型部署到消费级设备上,如智能手机和笔记本电脑。更令人振奋的是,它能够在显著减小模型体积的同时,几乎不牺牲性能。
什么是HIGGS?
HIGGS(Hadamard Incoherence with Gaussian MSE-optimal GridS) 是一种高效的无数据量化方法,旨在降低大型语言模型的存储和计算需求。与传统压缩方法不同,HIGGS具有以下特点:
无需额外数据:许多压缩方法依赖大量校准数据来优化模型,而HIGGS完全不需要这些。 无需梯度下降:HIGGS避免了复杂的参数优化过程,大幅简化了量化步骤。 高效且易用:该方法可以在普通设备上几分钟内完成量化,无需工业级硬件支持。
通过HIGGS,研究人员成功压缩了多个热门语言模型,包括LLaMA 3.1、LLaMA 3.2、DeepSeek和Qwen系列,证明了其广泛的适用性。
为什么HIGGS如此重要?
1. 降低硬件门槛
过去,压缩大型语言模型通常需要强大的服务器和昂贵的GPU,耗时数小时甚至数周。而HIGGS将这一过程缩短到几分钟,并可在普通笔记本电脑或智能手机上完成。这使得更多开发者和小型企业能够轻松尝试和部署这些模型。
2. 保持高质量输出
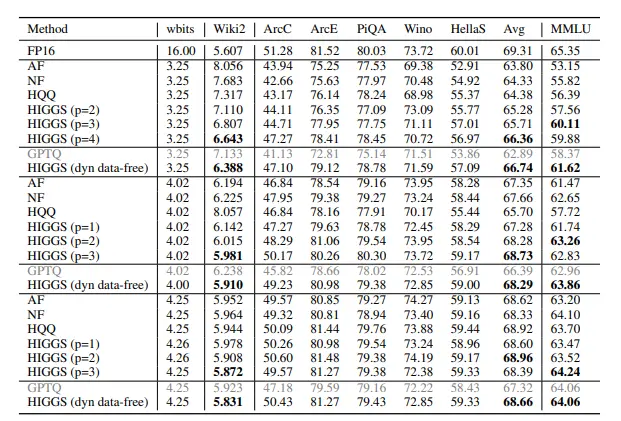
实验表明,HIGGS在模型质量和大小之间实现了出色的平衡。与现有的无数据量化方法(如NF4和HQQ)相比,HIGGS在压缩后的性能表现更加优秀,质量损失极小。
3. 推动模型普及
通过HIGGS,像DeepSeek R1(6710亿参数)和Llama 4 Maverick(4000亿参数)这样的超大规模模型,现在可以在资源受限的环境中使用。这为初创公司、独立开发者以及学术研究提供了更多可能性。
HIGGS的实际应用
HIGGS的出现不仅是一项技术突破,更为实际应用场景打开了新的大门:
移动设备上的AI助手
压缩后的模型可以部署在智能手机上,为用户提供实时的语言处理服务,例如翻译、文本生成和问答系统。低成本原型开发
开发者可以用HIGGS快速测试新想法,而无需担心高昂的计算成本。Yandex团队已经在内部使用该方法加速产品原型设计。教育与科研
学术机构和个人研究者可以通过HIGGS轻松获取和实验大型语言模型,从而推动更多创新。边缘计算
在网络连接不稳定或隐私要求高的场景中,HIGGS使本地运行大型模型成为可能,减少了对外部服务器的依赖。
HIGGS的技术亮点
HIGGS的核心优势在于其独特的设计思路和技术实现:
无数据量化
HIGGS不依赖额外的校准数据,避免了数据收集和预处理的复杂性。高效的压缩算法
通过Hadamard变换和Gaussian MSE优化,HIGGS在保证模型性能的同时,最大限度地减少了存储和计算需求。广泛的兼容性
该方法适用于多种主流语言模型,包括LLaMA、DeepSeek和Qwen等,展现了良好的通用性。
HIGGS与其他压缩方法的对比
| 方法 | 是否需要额外数据 | 硬件需求 | 质量损失 | 压缩速度 |
|---|---|---|---|---|
| NF4 | 需要 | 高性能GPU | 中等 | 慢 |
| HQQ | 需要 | 高性能GPU | 较低 | 中等 |
| HIGGS | 不需要 | 普通设备即可 | 极低 | 快速 |
从表格可以看出,HIGGS在多个维度上均优于现有方法,尤其是在硬件需求和压缩速度方面表现出色。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











