
滑铁卢大学、矢量研究所和零一万物的研究人员推出VISTA框架,旨在通过视频时空增强技术,提升对长时和高分辨率视频的理解能力。VISTA通过从现有的视频-字幕数据集中合成长时和高分辨率视频指令对,以增强模型处理长视频和高分辨率视频的能力。
例如,有一个视频监控场景,需要识别和分析一个商场内的人流动态。使用VISTA,可以从现有的视频数据中合成更长时和更高分辨率的视频,然后生成与这些视频相关的指令数据,如“描述视频中的人流高峰时段”。通过在这些合成数据上微调视频LMMs,可以提高模型在实际监控视频中识别和分析人流动态的能力。这有助于商场管理者更好地理解客流量变化,优化运营策略。
主要功能
VISTA的主要功能包括:
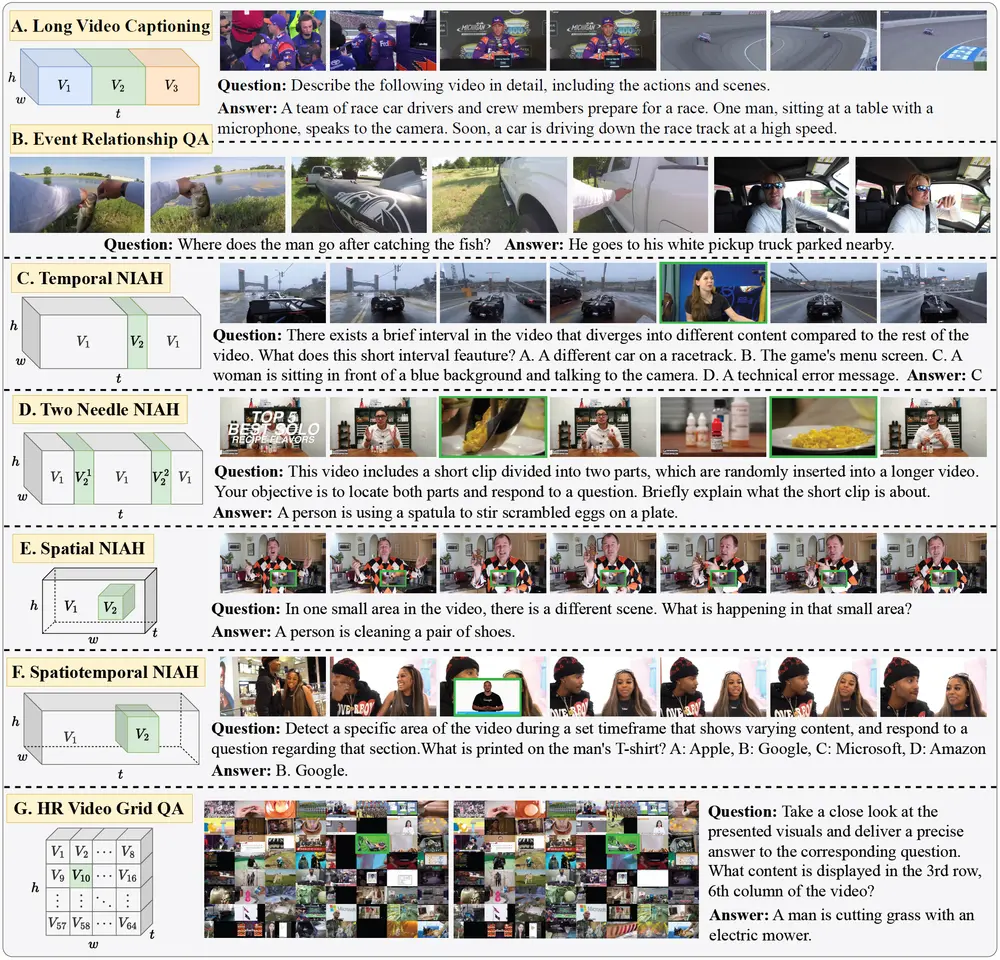
- 视频增强:通过时空组合现有视频以创建新的合成视频,这些视频具有更长的持续时间和更高的分辨率。
- 指令数据合成:基于新合成的视频生成相关问题-答案对。
- 模型微调:微调各种视频语言模型(LMMs),以提升其在长视频和高分辨率视频理解任务中的表现。
主要特点
- 数据为中心的方法:VISTA从数据增强的角度出发,通过合成数据来提升模型对长视频和高分辨率视频的理解能力。
- 多种视频增强技术:VISTA开发了七种视频增强方法,以提高视频的质量,使其更适合视频理解任务。
- 开放源代码和数据集:VISTA的所有源代码、策划的数据集以及衍生的模型都将在GitHub上公开,以促进社区进一步的研究和开发。
工作原理
VISTA的工作原理基于以下几个关键步骤:
- 视频混合和组合:VISTA利用图像和视频分类中的数据增强技术,通过空间和时间上组合视频,创建新的视频样本。
- 指令数据合成:使用高级语言模型Gemini-1.5-Pro来生成与新视频相关的指令数据。
- 数据集构建:基于现有公共视频字幕数据集构建VISTA-400K数据集,以改善视频LMMs处理长视频和高分辨率视频的能力。
- 模型微调:在VISTA-400K数据集上微调各种视频LMMs,以观察性能提升。

具体应用场景
VISTA可以应用于以下场景:
- 视频分析:在安全监控、内容审核等领域,VISTA可以帮助模型更好地理解和分析视频内容。
- 视频检索:在视频数据库中,VISTA可以提升视频检索系统的准确性和效率。
- 视频内容生成:在娱乐和媒体制作领域,VISTA可以用于生成具有更高质量和更长时长的视频内容。
- 视频问答系统:VISTA可以增强视频问答系统的能力,使其能够处理更复杂的视频内容和更详细的问题。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











