
腾讯ARC 实验室、清华大学和南京大学推出开源自回归图像生成模型Open-MAGVIT2 ,它致力于推广自回归视觉生成模型的使用。自回归模型是一种人工智能技术,可以根据一系列给定的数据点预测下一个数据点,这里特指在图像生成领域的应用。例如,你想要生成一张“阳光下的海滩”的图片,你可以将这个描述输入到 Open-MAGVIT2 模型中。模型会根据这个描述,通过其自回归的视觉生成能力,逐步构建出一张符合描述的海滩图片。这个过程中,模型会考虑到海滩上的细节,比如沙子的纹理、阳光照射的效果等,最终生成一张高质量的图像。
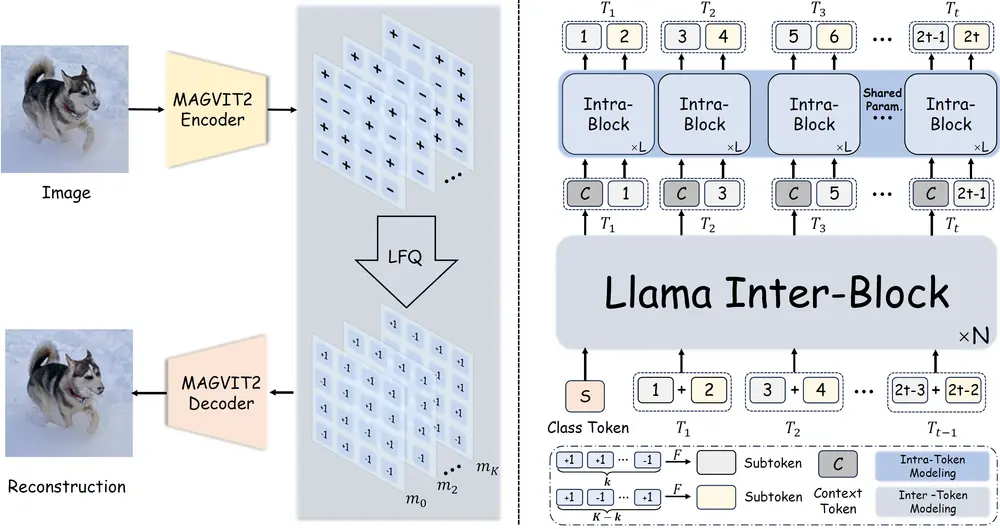
Open-MAGVIT2是一系列自回归图像生成模型,规模从 3 亿到 15 亿参数不等。Open-MAGVIT2 项目开源复制了 Google 的 MAGVIT-v2 分词器,该分词器拥有超大的码本(即 2^18 个码),并在 ImageNet 256x256 数据集上达到了最先进的重建性能(1.17 rFID)。此外,研究团队探索了其在纯自回归模型中的应用,并验证了其可扩展性特性。为了帮助自回归模型处理超大的词汇表,研究团队通过不对称的分词因子化将其分解为两个不同大小的子词汇表,并进一步引入了“下一个子词预测”,以增强子词之间的交互,从而提高生成质量。

主要功能:
- 图像重建与生成:Open-MAGVIT2 能够重建和生成高分辨率的图像。
- 自回归图像生成模型:提供了一系列不同大小的模型,从300M到1.5B参数不等,用于生成图像。
主要特点:
- 大规模码本的开源复制:项目复现了 Google 的 MAGVIT-v2 tokenizer,这是一个具有超大码本(2^18个码)的 tokenizer,并在 ImageNet 256x256 数据集上实现了最先进的重建性能。
- 不对称令牌分解:为了帮助模型处理超大词汇表,通过不对称令牌分解技术将码本分解为不同大小的两个子词汇表。
- “下一个子令牌预测”:引入了一种新的预测方法,增强了子令牌间的交互,以提高生成图像的质量。
工作原理:
- 视觉 Tokenizer:首先将输入的图像通过一个强大的视觉 tokenizer 转换为离散的 token 表示。
- 自回归变换器:然后,这些向量量化的序列被送入自回归变换器,进行 token 间和 token 内的关系建模,最终用于视觉合成。
具体应用场景:
- 图像合成:可以根据给定的文本描述生成相应的图像。
- 图像风格转换:可以学习一种图像的风格,并将其应用到另一张图像上。
- 数据增强:在训练机器学习模型时,可以用来生成额外的训练数据。
总的来说,Open-MAGVIT2 项目通过开源的方式,推动了自回归视觉生成技术的发展,使得研究者和开发者能够更容易地访问和利用这种先进的图像生成技术。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











