
中山大学 & 360人工智能研究院的研究人员推出一种新的人工智能模型PT-DiT,它是一种针对文本到任意任务(如文本到图像、文本到视频等)的高效能扩散变换器。这个模型特别关注于提高计算效率,减少冗余计算,同时保持或提升生成图像和视频的质量。例如,你给这个模型一个文本描述:“一只在森林环绕的宁静湖泊旁休息的鹿。” 这个模型能够根据这个描述生成一幅高分辨率的图像,甚至可以生成一段视频,展示这个场景的动态变化。在这个过程中,模型通过代理令牌机制高效地处理视觉信息,减少了计算资源的需求,使得生成过程更加快速和经济。
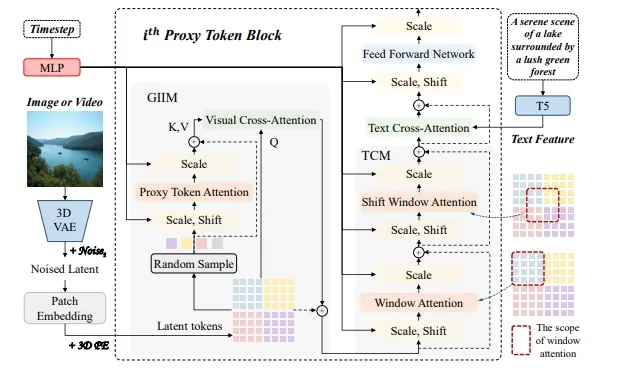
PT-DiT通过稀疏的代表性标记注意力(其中代表性的标记数量远小于总标记数量)来有效地建模全局视觉信息。具体来说,在每个变换器块中,研究团队从每个时空窗口中随机抽取一个标记作为该区域的代理标记。全局语义通过这些代理标记的自注意力捕捉,并通过交叉注意力注入到所有潜在标记中。同时,研究团队引入了窗口和移位窗口注意力来解决稀疏注意力机制在细节建模方面的局限性。基于精心设计的 PT-DiT,研究团队进一步开发了 Qihoo-T2X 家族,其中包括用于 T2I、T2V 和 T2MV 任务的各种模型。实验结果表明,PT-DiT 在图像和视频生成任务中实现了具有竞争力的表现,同时减少了计算复杂度(例如,相比 DiT 减少了 48%,相比 Pixart-α 减少了 35%)。
主要功能:
- 高效能的文本到多任务生成:PT-DiT能够根据文本描述生成图像、视频等,且在生成过程中注重计算效率。
- 减少计算复杂度:通过代理令牌(proxy token)机制,减少在模型中进行全局自注意力计算时的冗余。
主要特点:
- 代理令牌注意力机制:在每个变换器(transformer)块中,从每个空间-时间窗口随机抽取一个代表令牌作为该区域的代理,通过这些代理令牌进行自注意力计算,然后将全局语义信息注入所有潜在令牌。
- 窗口和移位窗口注意力:为了解决由于稀疏注意力机制导致的详细建模限制,引入了窗口和移位窗口注意力机制。
工作原理:
- 重塑操作:首先恢复令牌序列的空间和时间关系。
- 代理令牌采样:在局部空间区域和时间帧中随机抽取代表令牌,形成代理令牌集合。
- 自注意力和交叉注意力:通过代理令牌之间的自注意力交互,以及代理令牌和所有潜在令牌之间的交叉注意力,实现全局信息的捕获和传播。
- 窗口和移位窗口注意力:增强细节纹理建模能力,避免局部窗口注意力造成的“网格”现象。
具体应用场景:
- 文本到图像(Text-to-Image):根据文本描述生成高分辨率的图像。
- 文本到视频(Text-to-Video):根据文本描述生成视频内容,支持长视频的生成。
- 文本到多视图(Text-to-Multi-View):生成根据文本描述的多个视角的图像或视频。
总的来说,PT-DiT模型通过创新的代理令牌注意力机制,有效地平衡了生成质量和计算效率,为文本到图像、视频等多任务生成领域提供了一个有力的工具。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











