
来自萨特希尔风险投资公司的研究人员推出新型多模态图像生成系统MUMU,MUMU的核心能力是从文本和图像混合提示(multimodal prompts)生成图像。简单来说,用户可以提供一些文本描述和参考图片,MUMU能够理解这些信息并创作出新的图像,这些图像将结合文本描述的内容和参考图片的风格。这项技术展示了多模态模型在图像生成领域的潜力,特别是在需要将文本描述与视觉风格结合起来创造新图像的场景中。论文还讨论了MUMU的局限性和未来的研究方向,比如提高小细节的一致性、改进数据集的构建和评估方法等。
例如,用户想要生成一幅画,描述为“一个男人和他的狗在一个动画风格的卡通中”。用户可以提供一张男人的照片和一张卡通风格的参考图片。MUMU能够理解这些输入,并生成一张新的图像,展示这个男人以卡通风格与他的狗在一起的场景。

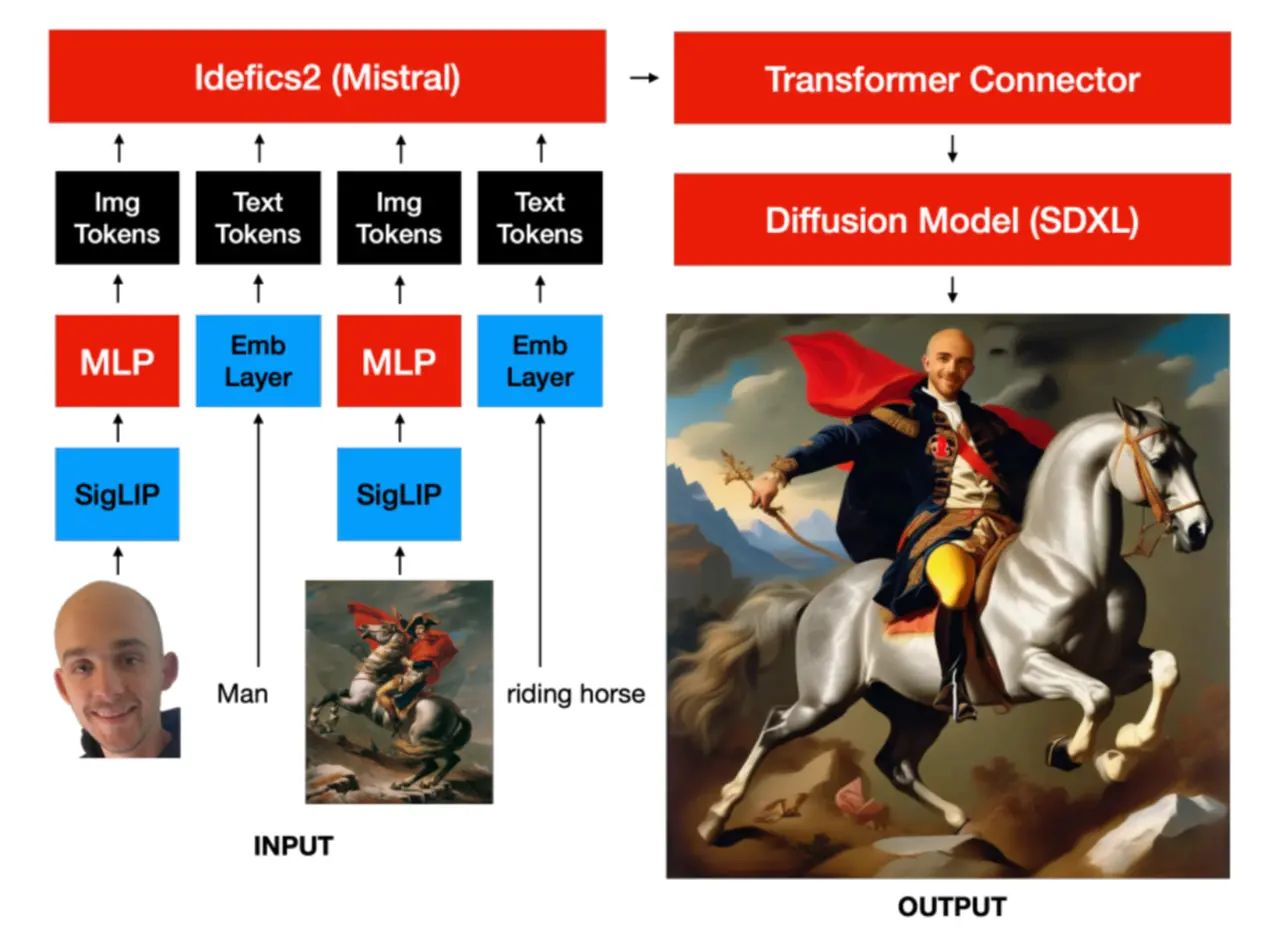
MUMU能够依据文字与图像交错的多模态指令生成图像,例如:“一位<男人的形象>与其<爱犬的图片>在<卡通场景>中的动画风格呈现”。为了启动这个多模态数据集,研究团队从合成的及公开的文本-图像资源的图片描述中提炼出与词汇语义匹配的、有意义的图像片段。MUMU设计包含了一个视觉-语言模型的编码器以及一个扩散解码器,并仅在一个配置了8xH100 GPU的单节点上完成训练。值得注意的是,尽管MUMU仅接受源自同一张图片的局部训练,它却能灵活地将多个不同图片的元素整合为统一且协调的输出画面。举例来说,当输入为一个写实人像与卡通画时,MUMU能够输出该人物以卡通形式展现的画面;而输入为站立的人物与滑板车图像时,输出则会是该人物正在骑行滑板车的场景。这样一来,MUMU展现出对风格转换及角色一致性维持等任务的良好泛化能力。
主要功能:
- 多模态输入理解:MUMU能够理解混合了文本和图像的复杂提示。
- 图像生成:根据用户的文本描述和提供的参考图片,生成新的图像。
主要特点:
- 自举(Bootstrapping):MUMU通过提取现有文本-图像数据集中的图像区域来构建训练集,这些图像区域与文本描述中的单词相对应。
- 多模态融合:MUMU将视觉-语言模型编码器与扩散解码器结合,能够处理来自不同图像的输入,并融合它们生成一致的输出。
工作原理:
- 数据集构建:使用现有的文本-图像数据,通过目标检测技术提取图像中与文本描述相匹配的区域。
- 模型训练:MUMU使用视觉-语言模型(如Idefics2)替换了传统扩散模型中的文本编码器,通过训练学习如何根据多模态提示生成图像。
- 图像生成:在生成图像时,MUMU能够将用户提供的多个图像融合,生成新的图像内容,例如将一个真实人物与卡通风格的图像融合,生成该人物的卡通版本。
具体应用场景:
- 艺术创作:艺术家可以使用MUMU将他们的概念草图转换成详细和风格化的艺术作品。
- 游戏开发:游戏设计师可以利用MUMU快速生成游戏角色和环境的原型图。
- 广告和营销:营销人员可以使用MUMU根据文本描述和风格要求,快速生成吸引人的广告图像。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











