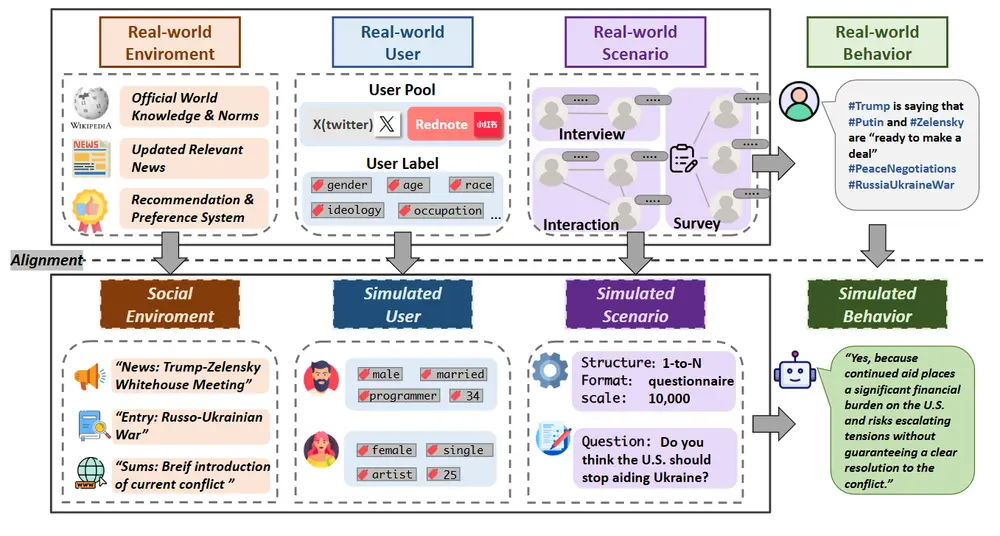
来自加州大学圣巴巴拉分校、谷歌和滑铁卢大学的研究人员推出文生视频新技术T2V-Turbo,它可以快速生成高质量的视频,并且能够根据文本描述来创建视频内容。它将来自混合的不同可微奖励模型的反馈整合到预训练的T2V模型的一致性蒸馏(Consistency Distillation, CD)过程中。开发人员直接优化与单步生成相关的奖励,这些生成自然源于计算CD损失的过程,有效地绕过了通过迭代采样过程反向传播梯度时的内存限制。例如,你想要创造一个视频,描述一个“在月光下的海滩上,一匹雄伟的白马正在优雅地奔跑”,T2V-Turbo能够理解你的描述,并快速生成这样一个视频。
- 项目主页:https://t2v-turbo.github.io
- GitHub:https://github.com/Ji4chenLi/t2v-turbo
- 模型地址:https://huggingface.co/jiachenli-ucsb/T2V-Turbo-VC2
- Demo:https://huggingface.co/spaces/TIGER-Lab/T2V-Turbo
目前T2V-Turbo还存在一些限制,比如使用的奖励模型(Rvid)并非专门针对视频-文本对的人类偏好进行训练的,未来的研究可能会探索更先进的Rvid以进一步提升性能。此外,论文强调了在发布模型时需要安装安全保障措施,以确保技术被负责任地使用。

主要功能:
- 根据文本描述生成视频。
- 快速生成视频,只需4-8个推理步骤。
主要特点:
- 快速生成:T2V-Turbo能够在更少的推理步骤下生成视频,相比传统的50步迭代采样过程,这是一个显著的速度提升。
- 高质量输出:即便在快速生成的过程中,T2V-Turbo也能保持视频的质量,满足用户对视频质量的期望。
- 混合奖励反馈:该技术集成了多种可微分奖励模型的反馈,以优化视频的生成过程。
工作原理:
- T2V-Turbo基于一个预训练的文本到视频(T2V)模型,并在一致性蒸馏(CD)过程中整合了不同奖励模型的反馈。
- 它使用图像-文本奖励模型(Rimg)来优化单个视频帧与人类偏好的一致性,同时使用视频-文本奖励模型(Rvid)来评估生成视频的时间动态和转换。
- 该技术避免了通过迭代采样过程中的反向传播来优化奖励,而是直接优化由CD损失计算产生的单步生成的奖励,有效绕过了传统方法面临的内存限制。

具体应用场景:
- 数字艺术创作:艺术家可以使用T2V-Turbo快速生成视频艺术作品。
- 社交媒体内容制作:用户可以利用T2V-Turbo生成社交媒体上的短视频内容。
- 电影和视频游戏制作:在电影或视频游戏的预制作阶段,T2V-Turbo可以用来快速生成概念视频。
- 广告行业:快速生成吸引人的视频广告,以较低的成本和时间投入达到良好的宣传效果。
- 教育和培训:在教育领域,T2V-Turbo可以用来制作教育视频,帮助解释复杂的概念或历史事件。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











