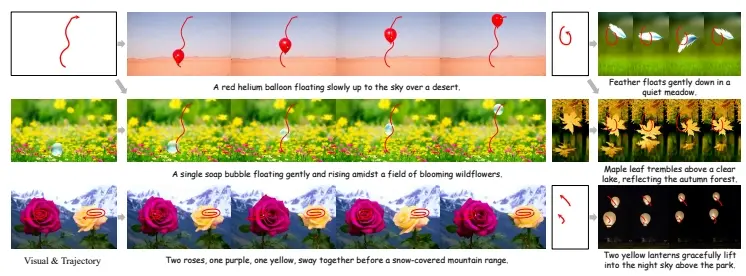
谷歌推出基于问答的自动评估指标Gecko2K,用于评估文生图模型的性能。文生图模型生成的图像并不总是能够完全符合文本中的所有细节。因此,评估这些模型生成的图像与文本描述的匹配程度是一个重要的研究问题。例如,我们有一个文本提示:“一只穿着教授服装的卡通猫,正在写一本书,书名是‘如果一只猫写了一本书?’”。一个文生图模型可能会生成一个高质量的图像,但图像中的猫没有穿着教授服装或者没有在写书。谷歌提出的方法可以帮助我们更准确地评估这种图像与文本描述之间的匹配程度。通过这种方法,我们可以更好地理解模型的强项和弱点,并指导未来的模型改进。
主要功能:
- 评估T2I模型的图像与文本的匹配度:即判断生成的图像是否准确地反映了文本中的信息。
主要特点:
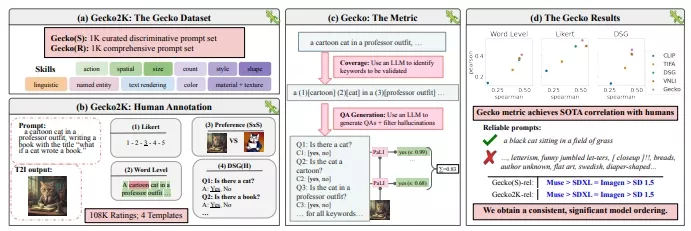
- 技能基础的基准测试(Gecko2K):这是一个新的基准测试,它通过不同的子技能(sub-skills)来评估模型在各种文本提示下的表现。
- 人类评分的广泛收集:研究者们收集了超过100K的注释,这些注释涵盖了四种不同的文本提示模板和四种T2I模型。
- 新的自动评估指标(Gecko):这是一个基于问题回答(QA)的自动评估指标,它与人类评分的相关性比现有指标更好。
工作原理:
- 创建文本提示集:研究者们开发了一组文本提示,这些提示覆盖了多种技能和子技能,以便全面评估T2I模型。
- 设计人类评分实验:通过不同的评分模板收集人类对图像-文本匹配度的判断。
- 开发评估指标:提出了一个新的评估指标Gecko,它通过生成问题-答案对(QA对)并使用大型语言模型(LLM)和视觉-语言模型(VLM)来评估图像和文本的一致性。
具体应用场景:
- 模型比较:使用Gecko2K基准测试和Gecko评估指标来比较不同T2I模型的性能。
- 技能识别:通过细分的技能提示,识别和改进模型在特定技能上的不足,例如文本渲染、空间关系理解等。
- 数据集构建:创建一个平衡的、覆盖多种技能的数据集,用于训练和测试T2I模型。
- 自动评估:在没有人类评分的情况下,使用Gecko指标来自动评估T2I模型的输出质量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











