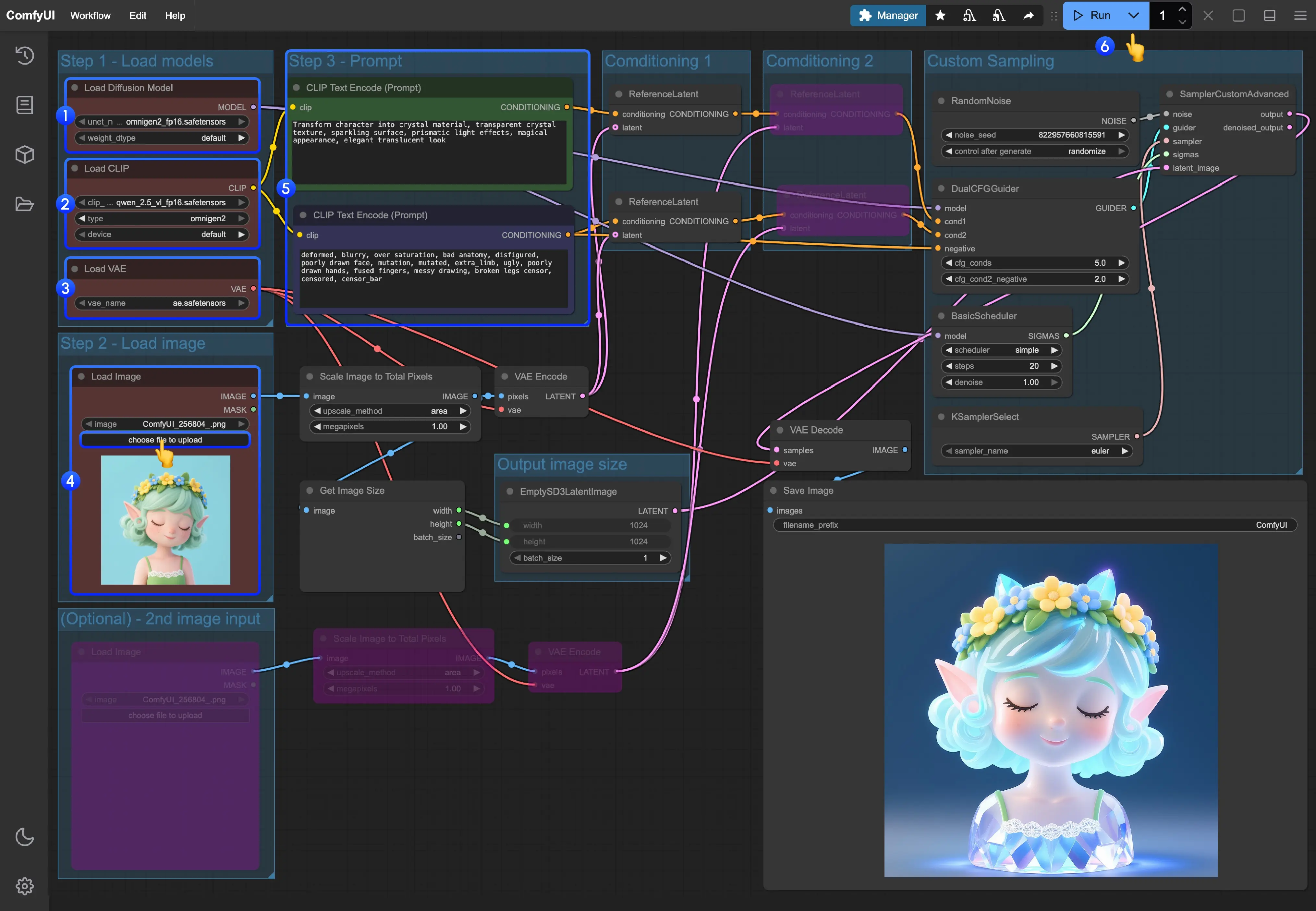
对于低显存的朋友,Wan2.1-T2V-1.3B模型是个不错的视频生成模型,开发者Evados为大家精心微调了一系列适合ComfyUI的Wan2.1-T2V-1.3B模型,这些模型经过实验优化,能够带来更出色的视觉效果和更高效的创作体验。
- 模型:https://huggingface.co/Evados/DiffSynth-Studio-Lora-Wan2.1-ComfyUI
- 镜像:https://hf-mirror.com/Evados/DiffSynth-Studio-Lora-Wan2.1-ComfyUI
模型简介
Evados训练的实验版本Wan2.1 v1.3b模型,这些模型经过不同程度的精炼、高分辨率优化,虽然目前还未经过全面测试,但从初步结果来看,表现相当不错。你可以根据需要生成4、5、6、8、10甚至更多步的视频。开发者会在后续版本中修复可能出现的问题,目前测试结果显示运行良好,但仍有改进空间。
如果你对这些模型感兴趣,可以尝试找到合适的ComfyUI工作流程来进行测试。不过,在使用过程中需要注意以下几点:
- 高步数的使用建议:当步数较高时,建议尝试使用其他采样器(如Euler),并调整不同的调度器。同时,可能需要增加CFG值。一般来说,步数越高,动画效果越流畅,但生成时间也会更长;步数较低时,动画可能会显得更随机。如果视频颜色过于强烈,可以尝试降低CFG值或使用较低版本的模型。例如,当步数达到20或更多时,建议使用较低版本的模型,并调整CFG来校正颜色。需要注意的是,这些模型经过了修改,其行为可能与原始模型有所不同。
- 模型优化方向:开发者发现这些模型在近景下表现良好,但背景可能会出现一些模糊问题。本周末,开发者将尝试修复这一问题,并可能会对模型进行更新,将所有模型精简到三四个版本。虽然性能有所提升,但开发者在测试中发现背景比原始版本更模糊,目前还在寻找原因。如果需要修复,可能需要重新制作模型。因此,如果你喜欢某个模型,请务必先保存下来,因为开发者会在周末删除旧版本,以便更新新版本并附带其他工作流程。
LoRA模型详解
接下来,让我们详细了解一下这些LoRA模型的特点和使用方法。
Wan2.1-1.3b-lora-aesthetics-v1
- 模型概述:此LoRA模型基于Wan2.1-1.3B模型,使用DiffSynth-Studio框架训练,专注于美学数据集的微调,能够提升生成视频的视觉吸引力。此外,还可以禁用无分类器引导以加快处理速度。
- 推荐设置:
cfg_scale = 1sigma_shift = 10
- 注意事项:使用此模型可能会降低生成视频的多样性。建议调整
lora_alpha值,以微调LoRA对最终输出的影响。
Wan2.1-1.3b-lora-speedcontrol-v1
- 模型概述:此LoRA模型同样基于Wan2.1-1.3B模型,使用DiffSynth-Studio框架训练,专注于提升生成视频的视觉效果。它可以通过调整LoRA alpha参数来控制生成视频的速度。
- 速度控制参数:
LoRA alpha > 0:速度较慢,图像质量提升。LoRA alpha < 0:速度较快,图像质量降低。
- 推荐设置:
cfg_scale = 1sigma_shift = 10
- 注意事项:使用此模型后,生成视频的多样性可能会减少。建议调整
lora_alpha值,以控制LoRA对最终输出的影响。目前,此模型的效果尚未完全稳定,仍在优化中。 - 模型效果示例:
- 提示词:纪录片风格的照片:一只活泼的小白狗快速跑过郁郁葱葱的绿色草坪。它的毛是亮白色,两只耳朵直立,表情专注而愉悦。阳光照亮它的毛皮,使其看起来格外柔软闪亮。背景是一片广阔的草地,点缀着几朵野花,一直延伸到地平线,地平线上是蓝天和几朵白云。视角动态,捕捉到狗的运动和周围草地的能量。侧面视角,中景,移动镜头。
- 负面提示词:颜色过于明亮,过曝,静态,模糊细节,字幕,艺术风格,绘画,静止图像,灰色调,非常低质量,低质量,JPEG压缩伪影,丑陋,畸形,多余的手指,手画得不好,脸部扭曲,畸形,四肢畸形,手指融合,静态场景,杂乱背景,三条腿,背景人群,角色倒着走。
- LoRA Alpha参数效果:
LoRA alpha = 0.7:速度较慢,视觉质量更好。LoRA alpha = 0:正常速度,中性效果。LoRA alpha = -0.5:速度较快,视觉质量降低。
Wan2.1-1.3b-lora-highresfix-v1
- 模型概述:此LoRA模型基于Wan2.1-1.3B模型,使用DiffSynth-Studio框架训练。由于基础模型最初在480p分辨率下训练,清晰度有一定限制。为此,进行了额外训练以提升高分辨率视频的质量,防止图像崩坏或显得暗淡。
- 推荐用法:
- 直接生成短时高分辨率视频:将分辨率设置为1024×1024,同时略微减少帧数以避免生成时间过长。
- 精修高分辨率视频细节:
- 首先生成低分辨率视频。
- 应用升频提升分辨率。
- 最后使用此模型增强视觉细节。
- 模型效果示例:
- 动画/2D风格提示词:动画风格,一个可爱的短黑发2D风格女孩,头发随风飘动,轻轻转头。
- 负面提示词:颜色过于明亮,过曝,静态,模糊细节,字幕,艺术风格,绘画,静止图像,整体色调暗淡,低质量,可见的JPEG压缩,丑陋,不完整,多余的手指,手画得不好,脸部畸形,变形,扭曲,四肢畸形,手指融合,静态图像,杂乱背景,三条腿,背景人群,倒着走。
- 剑与魔法提示词:古老神话场景,描绘英雄与龙的战斗,背景是陡峭的悬崖。英雄身穿盔甲,手持闪耀的剑,龙展开巨大的翅膀,准备喷火。
- 负面提示词:颜色过于明亮,过曝,静态,模糊细节,字幕,艺术风格,绘画,静止图像,整体色调暗淡,低质量,可见的JPEG压缩,丑陋,不完整,多余的手指,手画得不好,脸部畸形,变形,扭曲,四肢畸形,手指融合,静态图像,杂乱背景,三条腿,背景人群,倒着走。
Wan2.1-1.3b-lora-exvideo-v1
- 模型概述:此LoRA模型基于Wan2.1-1.3B模型,使用DiffSynth-Studio框架训练。它支持视频时长扩展,启用后可生成比平时长一倍的视频。
- 推荐设置:
num_frames = 161lora_alpha = 1.0
- 模型效果示例:
- 纪录片摄影风格提示词:一只戴着黑色太阳镜的顽皮小狗快速跑过绿色草坪。它的毛是浅棕色,耳朵竖起,表情专注而愉悦。阳光照亮它的毛皮,使其显得格外柔软闪亮。背景是一片广阔的草地,点缀着几朵野花,在蓝天和散布的白云下延伸。视角动态,捕捉到狗奔跑的动作和周围景观的活力。侧面移动镜头,中景。
- 高清3D纹理提示词:一只小白猫在10米高的平台上向前冲刺,然后后空翻跳入水中。它的毛柔滑,眼神锐利,动作流畅自然。背景是一个纯净的蓝色游泳池,水面平静光滑。跳跃时,头顶的聚光灯照亮猫咪,形成明暗对比。水花清晰精准,视觉效果惊艳。C4D渲染,动态特写。
- 日本动画风格提示词:在城市街角,一只黑猫蹲在路灯下,凝视远处的霓虹灯。突然,一道蓝色光束从天而降,迅速包裹它的身体。猫开始漂浮,黑毛慢慢消散,身体拉长。毛皮变成光滑的黑色西装,显露出纤细的身影。猫耳消失,面部特征变成人类模样,成为一个眼神冷峻的英俊年轻人。他轻盈落地,西装在夜风中微微飘动,蓝光逐渐消散——一个优雅而神秘的未来年轻人。
- 广角城市场景提示词:镜头俯瞰繁忙的城市街道。在宽阔的人行道上,行人来来往往,构成一个生动而动态的城市画面。
- 使用说明:此LoRA模型旨在延长视频时长并保持视觉质量。为获得最佳效果,请将
num_frames设置为161或根据需求调整。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











