Genmo是一家专注于视频生成的AI初创公司,之前都是默默无闻,其官方视频生成产品也是半死不活,但他们在昨天突然放大招开源了一款视频生成模型Mochi 1,号称其性能可与领先的闭源/专有竞争对手(如Runway的Gen-3 Alpha、Luma AI的Dream Machine、快手可灵、Minimax的海螺等)相媲美或超越。目前释出的Mochi 1只是预览版,仅能生成480P视频,更强大的 HD 版本预计将于今年晚些时候推出。
- GitHub:https://huggingface.co/genmo/mochi-1-preview
- 模型:https://huggingface.co/genmo/mochi-1-preview
- 官方Playground:https://www.genmo.ai/play
Mochi 1预览版基于Apache 2.0 协议,完全开源可商用,不过该模型需 4 块英伟达H100 显卡才可运行,官方提供了在线试用,目前需要排队等待。不过已经有开发者在准备压缩该模型让大家可以在ComfyUI上于本地运行。
- ComfyUI插件:https://github.com/kijai/ComfyUI-MochiWrapper
- 模型:https://huggingface.co/Kijai/Mochi_preview_comfy
Genmo宣布推出 Mochi 1研究预览版,这是他们最新的开源视频生成模型。Mochi 1 在运动质量和提示遵循方面取得了显著的进步,并根据 Apache 2.0 许可证免费提供给个人和商业用户使用。
Genmo 已经完成了由 NEA 领投的 2840 万美元 A 轮融资,参与者包括 The House Fund、Gold House Ventures、WndrCo、Eastlink Capital Partners、Essence VC,以及天使投资人 Abhay Parasnis(Typespace 的 CEO)、Amjad Masad(Replit 的 CEO)、Sabrina Hahn、Bonita Stewart 和 Michele Catasta。
Genmo团队使命是解锁人工通用智能的右脑。Mochi 1 是构建世界模拟器的第一步,这些模拟器可以想象任何可能或不可能的事物。Genmo团队包括 DDPM(去噪扩散概率模型)、DreamFusion 和 Emu Video 等项目的核心成员。Genmo 由领先的技术专家提供建议,包括 Ion Stoica(Databricks 和 Anyscale 的执行主席兼联合创始人)、Pieter Abbeel(Covariant 的联合创始人,OpenAI 的早期团队成员)和 Joey Gonzalez(语言模型系统的先驱,Turi 的联合创始人)。
评估
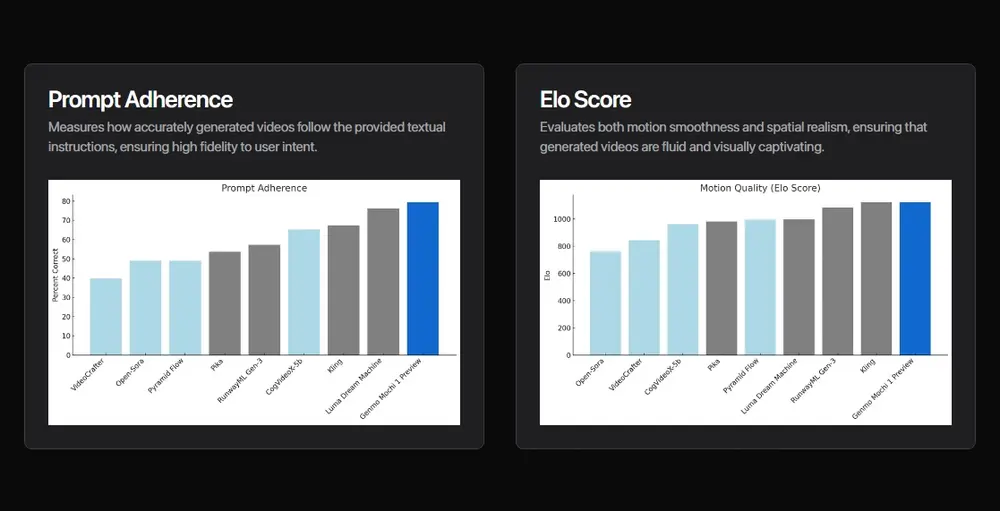
今天,视频生成模型与现实之间存在巨大的差距。运动质量和提示遵循是视频生成模型仍然缺失的两个最关键的能力。Mochi 1 为开源视频生成设定了新的最佳标准。它还与领先的闭源模型表现非常竞争。具体来说,Mochi 1研究预览版具有强大的:
- 提示遵循:展示了与文本提示的卓越对齐,确保生成的视频准确反映给定的指令。这使用户能够详细控制角色、设置和动作。我们使用自动化指标对提示遵循进行基准测试,使用视觉语言模型作为法官,遵循 OpenAI DALL-E 3 的协议。我们使用 Gemini-1.5-Pro-002 评估生成的视频。
- 运动质量:Mochi 1 以每秒 30 帧的速度生成平滑的视频,持续时间长达 5.4 秒,具有高时间一致性和逼真的运动动态。Mochi 模拟物理现象,如流体动力学、毛发模拟,并表现出一致、流畅的人类动作,开始跨越恐怖谷。评估者被指示专注于运动而不是帧级美学(标准包括运动的趣味性、物理合理性和流畅性)。Elo 分数按照 LMSYS Chatbot Arena 协议计算。
限制
在研究预览版中,Mochi 1 是一个不断发展的模型。有一些已知的限制。初始版本目前仅能生成 480P视频。在某些极端运动的边缘情况下,也可能发生轻微的扭曲和失真。Mochi 1 还针对写实风格进行了优化,因此不适合动画内容。Genmo预计社区将微调模型以适应各种美学偏好。此外,Genmo在游乐场中实施了强大的安全审核协议,以确保所有视频生成保持安全和符合道德准则。
模型架构
Mochi 1 代表了开源视频生成领域的重大进步,采用了Genmo新颖的非对称扩散 Transformer(AsymmDiT)架构构建的 100 亿参数扩散模型。完全从头开始训练,它是迄今为止公开发布的最大的视频生成模型。最重要的是,它是一个简单、可改进的架构。
为确保开源社区能够运行我们的模型,效率至关重要。随 Mochi 一起,我们开源了视频 VAE。我们的 VAE 能够因果压缩视频至原始大小的 1/128,具体通过 8x8 的空间压缩和 6 倍的时间压缩,将视频转化为 12 通道的潜空间表示。
AsymmDiT 通过简化文本处理并将神经网络容量集中在视觉推理上,高效地处理用户提示和压缩视频 Token。AsymmDiT 通过多模态自注意力和为每种模态学习单独的 MLP 层,联合关注文本和视觉 Token,类似于 Stable Diffusion 3。然而,我们的视觉流通过更大的隐藏维度拥有近 4 倍的参数。为了在自注意力中统一模态,我们使用非平方的 QKV 和输出投影层,这种非对称设计降低了推理时的显存需求。
许多现代扩散模型使用多个预训练的语言模型来表示用户提示。相比之下,Mochi 1 简单地使用单个 T5-XXL 语言模型编码提示。
Mochi 1 通过完整的 3D 注意力机制,对 44,520 个视频Token的上下文窗口进行联合推理。为定位每个Token,我们将可学习的旋转位置嵌入(RoPE)扩展到三维。网络端到端学习空间和时间轴的混合频率。
Mochi 借鉴了语言模型扩展领域的最新进展,包括 SwiGLU 前馈层、用于增强稳定性的查询-键标准化,以及用于控制内部激活的三明治标准化。
开源发布
Genmo将在 Apache 2.0 许可证下发布 Mochi 1。围绕视频生成建立一个开放的研究生态系统至关重要。Genmo相信开源模型推动进步并使最先进的 AI 能力民主化。
应用
Genmo对 Mochi 1 的研究预览版在各个领域开启了新的可能性:
- 研究和开发:推进视频生成领域并探索新的方法论。
- 产品开发:在娱乐、广告、教育等领域构建创新应用。
- 创意表达:赋予艺术家和创作者使用 AI 生成的视频将他们的愿景变为现实。
- 机器人:为机器人、自动驾驶车辆和虚拟环境中的 AI 模型训练生成合成数据。
接下来是什么?
今天,Genmo发布了 Mochi 1 预览版,展示了 480p 基础模型的能力。但这只是一个开始。今年年底之前,Genmo将发布 Mochi 1 的完整版本,其中包括 Mochi 1 HD。Mochi 1 HD 将支持 720p 视频生成,具有增强的保真度和更平滑的运动,解决复杂场景中的扭曲等边缘情况。展望未来,Genmo正在开发图像到视频的能力。此外,Genmo专注于提高模型的可控性和可引导性,以使用户对其输出有更精确的控制。
未来愿景
Mochi 1 预览版有一些限制,包括 480p 分辨率,以确保在终端用户设备上的计算效率。展望未来,我们将继续推进视频生成领域的 SOTA,支持高分辨率、长视频生成以及图像到视频的生成。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











