
北京邮电大学、中国科学院计算技术研究所、大连理工大学和北京智源研究院的研究人员提出了一种名为 NOVA 的新型自回归视频生成模型。该模型能够在无需向量量化的情况下,通过重新表述视频生成问题,实现了在时间帧预测和空间集预测上的非量化自回归建模,显著提升了数据效率、推理速度、视觉保真度和视频流畅性。例如,给定一段描述“一个18世纪维多利亚式房屋的3D模型”,NOVA能够根据文本提示生成一个视频,展示房屋的旋转视角和细节。
- GitHub:https://github.com/baaivision/NOVA
- 模型:https://huggingface.co/collections/BAAI/nova-6761508d11ea198180aa2c7b
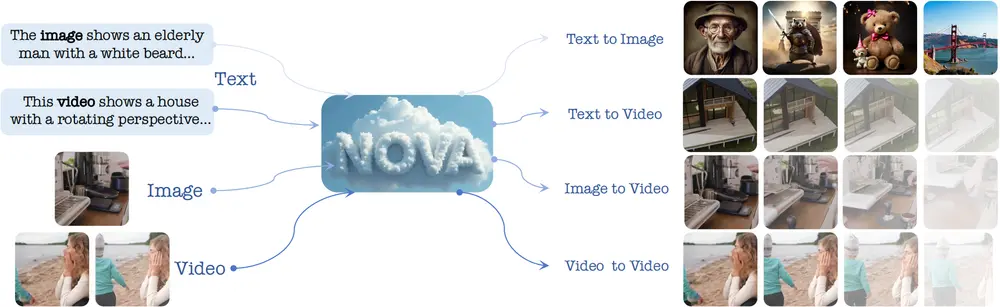

主要功能
NOVA的主要功能是将文本描述转换为视频内容,这包括从文本到图像(Text to Image)和从文本到视频(Text to Video)的生成任务。
主要特点
- 数据效率和推理速度:NOVA在数据效率、推理速度、视觉保真度和视频流畅性方面超越了以往的自回归视频模型。
- 模型容量小:即使模型参数数量较少(0.6B参数),NOVA也能实现出色的性能。
- 低成本训练:在文本到图像生成任务中,NOVA的训练成本远低于其他模型。
- 零样本泛化:NOVA能够在多种不同的上下文中进行零样本泛化,即在未见过的数据上也能表现出色。
主要创新点:
1. 重新表述视频生成问题
传统的自回归视频生成模型通常采用光栅扫描顺序(raster-scan order)或扩散模型中的固定长度令牌联合分布建模。这些方法虽然有效,但在灵活性和效率上存在局限。NOVA则提出了一个新的视角,将视频生成问题重新表述为时间帧预测和空间集预测的组合。
- 时间帧预测:NOVA保持了GPT风格模型的因果属性,确保未来帧的生成依赖于过去帧的信息,从而实现灵活的上下文能力。
- 空间集预测:在单个帧内,NOVA利用双向建模(bidirectional modeling),允许模型在同一帧的不同部分之间进行信息交换,提高了生成效率和质量。
2. 无需向量量化
与许多现有的自回归视频生成模型不同,NOVA无需向量量化(vector quantization)。向量量化通常用于将连续的像素值离散化,以便模型可以处理离散的令牌。然而,这种做法会引入额外的复杂性和潜在的失真。NOVA直接在连续空间中进行建模,避免了量化带来的信息损失,同时简化了模型结构,降低了训练和推理的成本。
3. GPT风格的因果属性与双向建模结合
NOVA结合了GPT风格的因果属性和双向建模的优势:
- 因果属性:在时间维度上,NOVA保持了因果关系,确保每一帧的生成只依赖于之前的帧,这有助于生成连贯的视频序列。
- 双向建模:在空间维度上,NOVA允许在同一帧内的不同区域之间进行双向信息传递,这不仅提高了生成效率,还增强了模型对局部细节的捕捉能力。
4. 小参数量下的高性能
尽管NOVA的参数量仅为0.6B,它在多个方面超越了现有的自回归视频生成模型:
- 数据效率:NOVA能够在更少的训练数据下达到更高的生成质量,减少了对大规模数据集的依赖。
- 推理速度:由于其高效的建模方式,NOVA的推理速度更快,适合实时应用。
- 视觉保真度:NOVA生成的视频在视觉上更加逼真,细节丰富,能够很好地保留原始视频的特征。
- 视频流畅性:NOVA生成的视频在时间维度上具有良好的连贯性和流畅性,避免了常见的抖动或不自然的过渡。
5. 超越图像扩散模型
NOVA不仅在视频生成任务中表现出色,还在文本到图像生成任务中超越了最先进的图像扩散模型。扩散模型通常需要大量的计算资源和较长的训练时间,而NOVA在保持高质量生成的同时,显著降低了训练成本。
6. 扩展视频时长的泛化能力
NOVA在生成长视频时表现出良好的泛化能力。它可以有效地扩展视频的时长,而不会出现明显的质量下降或内容重复。这一特性使得NOVA适用于生成长时间的视频内容,如电影片段或动画。
7. 多样化的零样本应用
NOVA的一个重要特点是它能够在统一模型中实现多样化的零样本应用。这意味着用户可以在没有额外训练的情况下,使用同一个模型完成不同的生成任务,例如从文本生成视频、从图像生成视频、甚至是跨模态的生成任务。这种灵活性使得NOVA在实际应用中具有广泛的应用前景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











