加州大学圣地亚哥分校 Hao AI 实验室推出的一个开源技术栈FastVideo ,旨在显著加速最先进的(SoTA)开源DiT架构视频生成模型的推理速度。它通过引入 一致性蒸馏(Consistency Distillation, CD) 技术,大幅减少了生成高质量视频所需的时间。目前,FastVideo 已经支持了 Mochi 和 Hunyuan 两个流行的DiT模型,并在多个基准测试中表现出色。
- GitHub:https://github.com/hao-ai-lab/FastVideo
- 模型:https://huggingface.co/FastVideo
- 量化版本:https://huggingface.co/Kijai/HunyuanVideo_comfy
主要特性
1. 显著提升推理速度
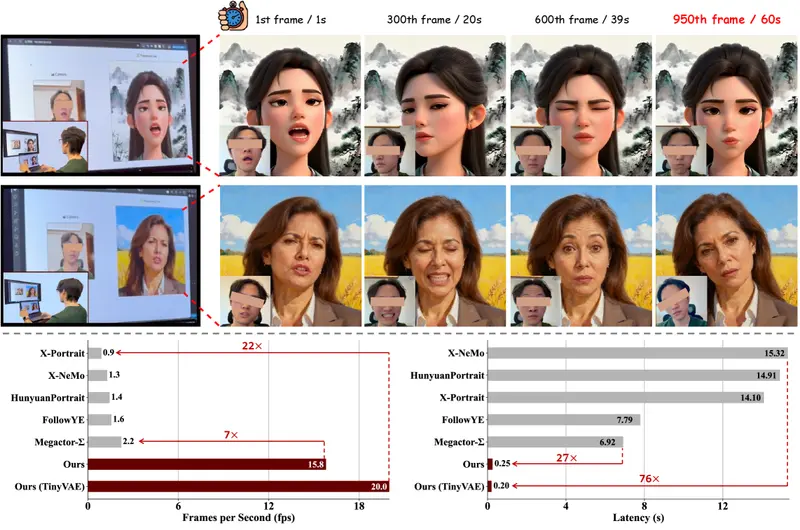
- Hunyuan Video:与原始版本相比,FastVideo 将扩散时间从 232 秒减少到 27 秒,端到端时间从 267 秒减少到 62 秒。
- Mochi:与原始版本相比,FastMochi 将扩散时间从 63 秒减少到 26 秒,端到端时间从 123 秒减少到 81 秒。
2. 一致性蒸馏(CD)技术
- CD 最初是为了加速图像扩散模型而提出的,FastVideo 将其应用于视频扩散变压器(DiT),并取得了显著的效果。CD 通过将大模型的知识传递给更小、更快的模型,从而实现了高效的推理加速。
3. 首个开源的视频 DiT 蒸馏方案
- FastVideo 提供了基于 Pseudo Consistency Modeling (PCM) 的开源蒸馏方案,用户可以根据该方案蒸馏自己的视频扩散模型。
4. 支持多种优化技术
- FSDP(Fully Sharded Data Parallelism):支持分布式训练,实现接近线性扩展至 64 个 GPU。
- 序列并行:优化模型的前向和反向传播过程,减少内存占用。
- 选择性激活检查点:进一步优化内存使用,提升训练效率。
- LoRA(Low-Rank Adaptation):支持轻量级微调,减少显存占用。
5. 内存高效的微调
- 支持 LoRA、预计算潜在变量和预计算文本嵌入,使得微调过程更加高效,尤其是在资源有限的情况下。
6. 可扩展性和灵活性
- FastVideo 是一个轻量级框架,易于集成和扩展。它不仅支持现有的 SoTA 模型(如 Mochi 和 Hunyuan),还可以用于其他视频扩散模型的加速。
7.模型
- FastMochi:FastMochi 是一个加速版的 Mochi 模型。它可以在 8 个扩散步骤内生成高质量视频,相比原始 Mochi 的 64 步,速度提升了约 8 倍。
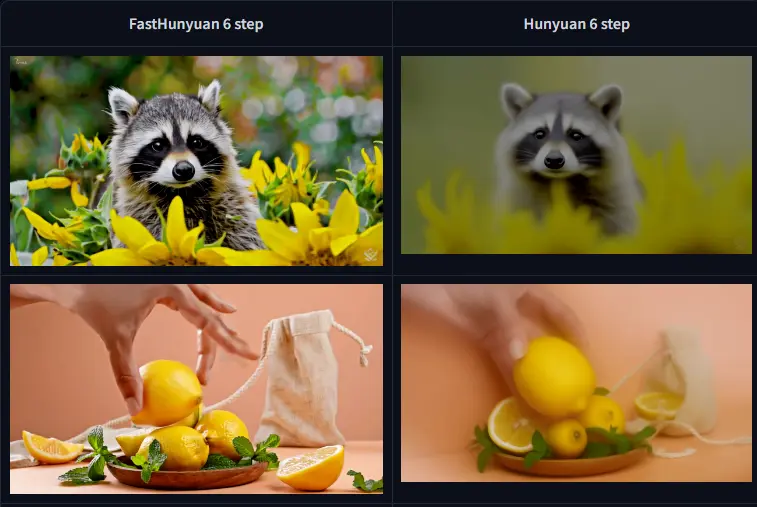
- FastHunyuan:FastHunyuan 是一个加速版的 HunyuanVideo 模型。它可以在 6 个扩散步骤内生成高质量视频,相比原始 HunyuanVideo 的 50 步,速度提升了约 8 倍。
未来发展方向
FastVideo 目前仍处于高度实验性阶段,开发团队将继续优化模型性能,并计划引入更多功能,包括但不限于:
- 支持更多的视频扩散模型。
- 进一步优化推理速度和内存使用。
- 提供更多的训练和微调选项。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











