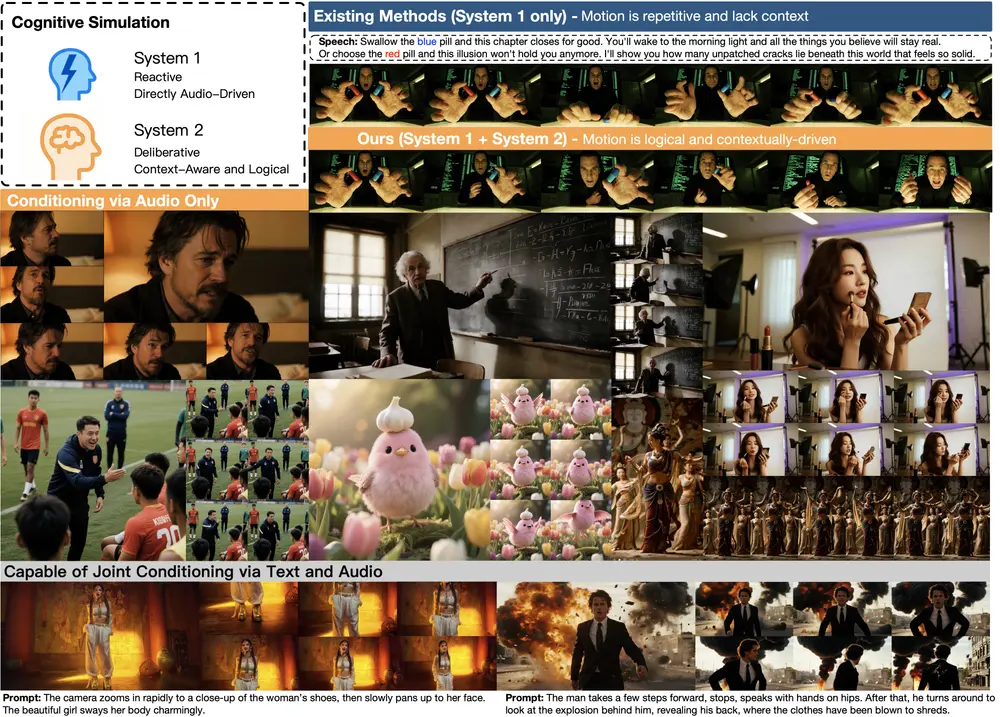
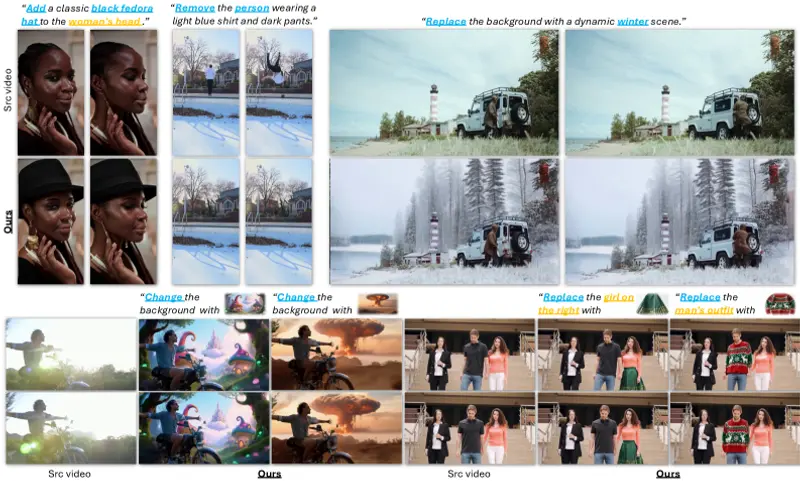
Rhymes AI在推出多模态原生模型Aria后,又在昨天开源了视频生成模型Allegro,Allegro 使用户能够从简单的文本提示生成高质量的 6 秒视频,帧率为 15 帧每秒,分辨率为 720P。这种质量水平允许高效地创建各种电影主题,从人物和动物的详细特写到基于文本描述的几乎任何场景。该模型的多功能性为用户提供了在 6 秒格式限制内探索多样化创意想法的灵活性。
- GitHub:https://github.com/rhymes-ai/Allegro
- 模型:https://huggingface.co/rhymes-ai/Allegro
- ComfyUI插件:https://github.com/bombax-xiaoice/ComfyUI-Allegro

主要特点:
- 开源:完整的模型权重和代码对社区开放,采用 Apache 2.0 许可证
- 多功能内容创作:能够生成广泛的内容,从人类和动物的特写到多样化的动态场景
- 高质量输出:生成 15 FPS、720x1280 分辨率的详细 6 秒视频,可通过 EMA-VFI 插值到 30 FPS
- 小巧高效:具有 175M 参数的 VAE 和 2.8B 参数的 DiT 模型。支持多种精度(FP32、BF16、FP16),在 BF16 模式下使用 9.3 GB 的 GPU 内存,并支持 CPU 卸载。上下文长度为 79.2k,相当于 88 帧
Allegro核心技术包括三个关键组件:
- 大规模视频数据处理
- 将原始视频压缩成视觉 Token
- 扩展视频扩散 Transformer
Allegro 背后的技术
该模型的能力建立在处理视频数据、压缩原始视频和生成视频帧的核心技术之上,从而实现将文本提示转化为短视频片段。
1. 大规模视频数据处理
为了创建一个能够生成多样化和逼真视频的模型,这需要一个系统来处理大量的视频数据。为此,Rhymes AI设计了系统的数据处理和过滤管道,从原始数据中提取训练视频。该过程是顺序的,包括以下阶段:

接下来,根据处理过程中获得的指标,Rhymes AI开发了一个结构化数据系统,允许对数据进行多维分类和聚类,便于模型在各个阶段和目的的训练和微调。
2. 将视频压缩成视觉 Token
视频生成中的一个关键挑战是处理大量的数据。为了解决这个问题,Rhymes AI在保留关键细节的同时将原始视频压缩成更小的视觉 Token,从而实现更流畅和高效的视频生成。具体来说,Rhymes AI设计了一个视频变分自编码器(VideoVAE),它将原始视频编码成时空潜在空间。VideoVAE 基于预训练的图像 VAE,扩展了时空建模层,以有效利用空间压缩能力。
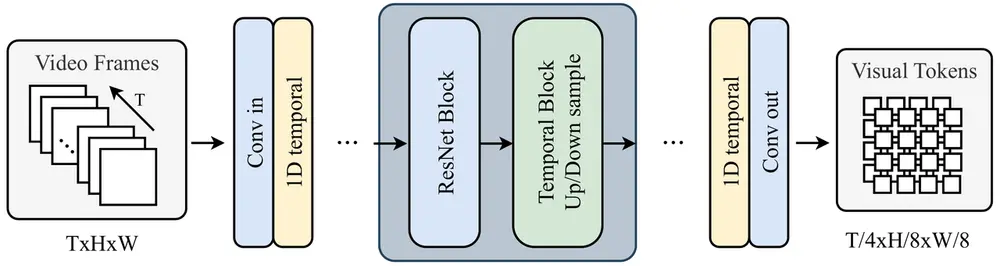
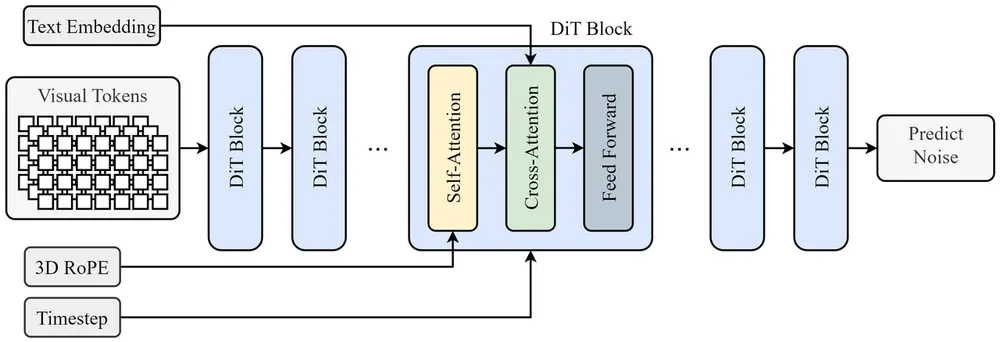
3. 视频扩散变换器(VideoDiT)
Allegro 视频生成能力的核心在于其扩展的DiT架构,该架构应用扩散模型生成高分辨率视频帧,确保视频运动的质量和流畅性。
Allegro 的骨干网络基于 DiT架构,具有 3D RoPE 位置嵌入和 3D 全注意力。该架构有效地捕捉视频数据中的空间和时间关系。
与使用 UNet 架构的传统扩散模型相比,Transformer 结构更有利于模型扩展。通过利用 3D 注意力,DiT 处理视频帧的空间维度和时间演变,从而更细致地理解运动和上下文。
3D 注意力机制和 DiT 模型的扩展能力相结合,显著提升了性能,使得生成高质量、细节丰富且运动流畅的视频成为可能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











