
北京大学、Hedra和英伟达的研究人员推出新型视频生成技术Magic 1-For-1 ,通过将复杂的文本到视频(T2V)生成任务分解为两个更简单的子任务:文本到图像(T2I)生成和图像到视频( I2V)生成。这种方法不仅简化了视频生成的流程,还通过一系列优化技巧,大幅减少了生成过程中的计算成本,使得视频生成更加高效。
例如,用户需要生成一个描述“在海边奔跑的少年”的视频。传统方法可能需要直接从文本生成视频,这通常计算量巨大且容易出现质量下降的问题。而 Magic 1-For-1 的方法是:
- 文本到图像:首先根据文本描述生成一张高质量的静态图像,例如少年在海边奔跑的场景。
- 图像到视频:然后以这张图像为基础,生成一段连贯的视频,少年在视频中奔跑、挥手等动作自然流畅。
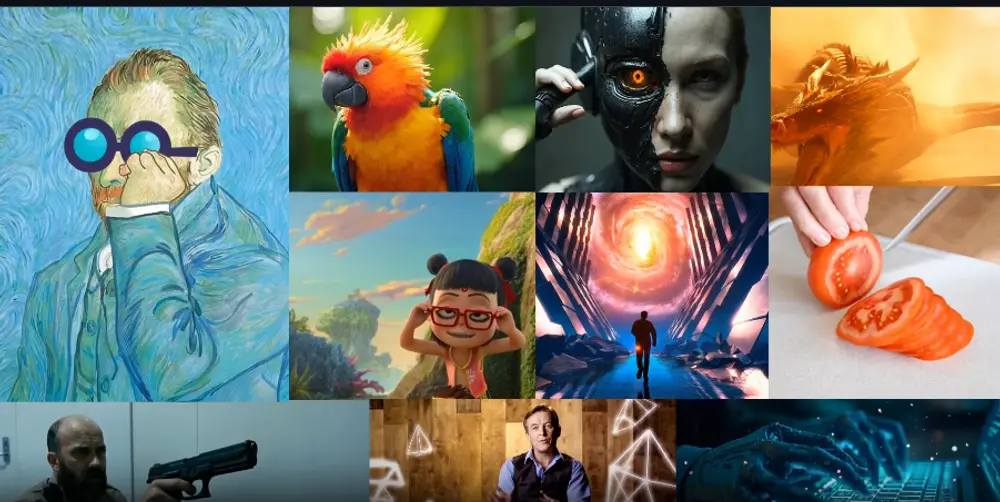
主要功能
Magic 1-For-1 的主要功能是高效生成高质量的视频内容,具体包括:
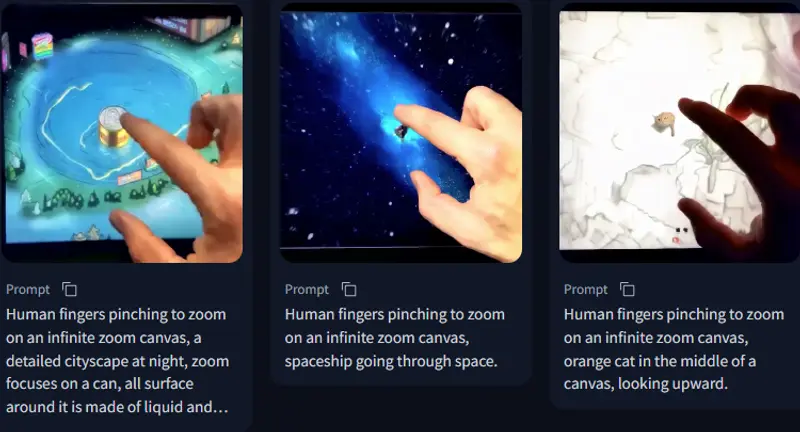
- 快速生成:能够在短时间内生成高质量的视频片段,例如在 3 秒内生成 5 秒的视频,通过滑动窗口技术在一分钟内生成一分钟的视频。
- 高质量输出:生成的视频在视觉质量、动态效果、主体一致性等方面表现出色,优于其他开源的图像到视频(TI2V)模型。
- 优化内存和计算成本:通过模型量化和参数稀疏化等技术,大幅减少了内存消耗和计算步骤,使得模型能够在消费级 GPU 上运行。
主要特点
- 任务分解:将复杂的 T2V 任务分解为 T2I 和 I2V 两个子任务,简化了生成流程。
- 多模态引导:结合文本和视觉输入,增强生成视频的语义对齐和上下文一致性。
- 加速技术:采用扩散步数蒸馏(diffusion step distillation)和分类器自由引导(classifier-free guidance, CFG)蒸馏等技术,显著加快了生成速度。
- 模型优化:通过 int8 量化等技术,将模型大小从 32GB 优化到 16GB,降低了内存占用。
工作原理
Magic 1-For-1 的工作原理基于以下核心步骤:
- 图像先验生成:使用扩散模型和检索增强技术生成高质量的初始图像。通过检索与文本描述相关的图像,作为生成过程中的额外条件信号。
- 图像到视频生成:将生成的图像作为视频的第一帧,通过 I2V 模型生成连贯的视频。模型通过多模态输入(文本和图像)增强生成效果。
- 扩散步数蒸馏:通过 DMD2 算法,将多步扩散模型蒸馏为少步生成模型,显著减少推理步骤。
- CFG 蒸馏:将传统的分类器自由引导计算简化为单次前向传播,进一步加快推理速度。
- 模型量化:采用 int8 权重量化,减少模型内存占用,同时保持生成质量。

具体应用场景
Magic 1-For-1 适用于多种需要高效视频生成的场景,包括但不限于:
- 内容创作:快速生成高质量的视频内容,如广告、短视频、动画等。
- 视频编辑:为视频编辑提供高质量的素材,例如生成特定场景或角色的视频片段。
- 实时视频生成:在需要快速响应的场景中,如直播互动、实时视频特效等。
- 教育与培训:生成教育视频,帮助学生更好地理解复杂的概念。
- 娱乐产业:为电影、电视剧等创作高质量的特效视频。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











