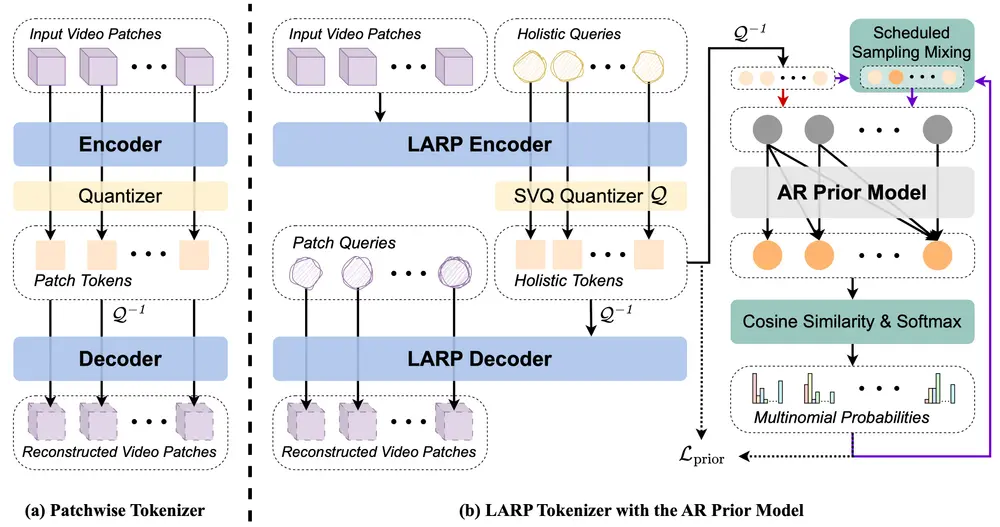
马里兰大学学院公园分校的研究人员提出了一种名为LARP(Latent Aggregation and Refinement for Perception)的新型视频分词器,它专为自回归(AR)生成模型设计,用于提高视频生成任务的性能。LARP通过引入一种全新的整体化(holistic)标记方案,能够捕捉视频内容的全局和语义信息,而不仅仅局限于局部视觉信息。
- 项目主页:https://hywang66.github.io/larp
- GitHub:https://github.com/hywang66/LARP
- 模型:https://huggingface.co/hywang66
例如,我们想要生成一段关于篮球比赛的视频。传统的视频分词器可能会将视频分解成许多小的视觉片段(patches),然后逐个编码成离散的标记。但这种方法可能无法捕捉到整个场景的全局信息,比如球员之间的互动或者比赛的流畅性。而LARP通过使用整体化查询(holistic queries),能够更好地理解和生成包含这些全局信息的视频内容。
主要功能:
LARP的主要功能是将连续的视频信号转换成一系列离散的标记(tokens),这些标记可以被自回归模型用于生成高保真度的视频。
主要特点:
- 整体化标记方案:LARP不直接编码局部视觉片段,而是通过学习到的整体化查询来捕获视频的全局信息。
- 灵活性:支持任意数量的离散标记,可以根据任务需求进行适应性标记。
- 自回归生成优化:通过在训练时集成轻量级的AR变换器(AR transformer)作为先验模型,优化了离散标记空间以适应AR生成任务。
- 顺序确定:在训练过程中自动确定离散标记的顺序,使得在推理时能够更平滑、更准确地进行AR生成。
工作原理:
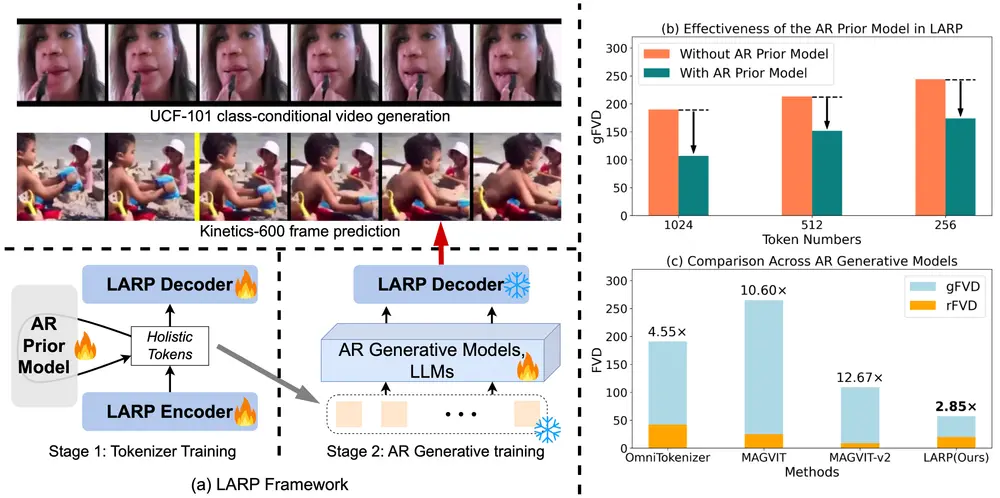
LARP的工作原理可以分为两个阶段:
- 标记器训练(Tokenizer Training):在这个阶段,LARP使用一个轻量级的AR先验模型来训练标记器,学习一个对AR友好的潜在空间。
- AR生成训练(AR Generative Training):在第二个阶段,AR生成模型在LARP的离散标记上进行训练,以合成高保真度的视频。
整体分词方案:
- 传统方法:传统的视频分词方法通常将局部视觉块直接编码为离散标记,这种方法虽然简单但往往只能捕捉到局部信息。
- LARP:LARP则使用一组学习的整体查询(global queries)从视觉内容中收集信息。这种方法不仅能够捕捉更多的全局和语义信息,还能提供更高的灵活性。
灵活的离散标记:
- LARP支持任意数量的离散标记,可以根据任务的具体需求进行自适应和高效的分词。这种灵活性使得LARP能够更好地适应不同的应用场景。
轻量级AR变压器:
- 为了使离散标记空间与下游AR生成任务对齐,LARP集成了一个轻量级的AR变压器作为训练时的先验模型。这个先验模型在离散潜在空间上预测下一个标记,从而帮助LARP学习到更有利于自回归生成的潜在表示。
逐步优化:
- 在训练过程中,先验模型逐步推动离散标记朝向最佳配置,确保在推理时实现更平滑和更准确的自回归生成。这种逐步优化的过程不仅提高了模型的训练效率,还增强了生成视频的质量。
技术优势
- 全局和语义表示:LARP能够捕捉更多的全局和语义信息,而不仅仅是局部块级别的信息,从而生成更丰富和连贯的视频内容。
- 灵活性:支持任意数量的离散标记,能够根据任务需求进行自适应和高效的分词。
- 优化的潜在空间:通过轻量级AR变压器的先验模型,LARP学习到的潜在空间不仅针对视频重建进行了优化,还以一种更有利于自回归生成的方式进行结构化。
- 顺序定义:在训练过程中为离散标记定义了一个顺序,确保在推理时实现更平滑和更准确的自回归生成。
实验结果
全面的实验表明,LARP在多个视频生成任务中表现出色。特别是在UCF101类条件视频生成基准测试中,LARP达到了最先进的FVD(Fréchet Video Distance)分数,显著优于现有的方法。
应用前景
LARP不仅增强了AR模型与视频的兼容性,还为构建统一的高保真多模态大语言模型(MLLMs)提供了新的可能性。这一技术的发展有望在视频生成、多模态交互和其他相关领域带来更多的创新和突破。
总之,LARP的提出标志着视频分词技术的一个重要进步,为未来的视频生成和多模态模型的发展奠定了坚实的基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...