
随着大型基础模型的发展和合成训练数据的广泛应用,单图像深度估计技术取得了显著进展,这重新激发了研究者对视频深度估计的兴趣。然而,直接将单图像深度估计器应用于视频每一帧的方法存在明显缺陷,如时间连续性忽略导致的闪烁问题,以及在相机运动引起深度范围突然变化时的失效。苏黎世联邦理工学院和卡内基梅隆大学的研究人员提出了一种创新的解决方案——RollingDepth。该模型通过结合单图像潜在扩散模型(LDM)和优化配准算法,实现了高效且准确的视频深度估计,尤其适用于长时间视频。RollingDepth能够从单目视频序列中推断出每一帧的密集深度信息,将2D视频转换为3D场景表示。这对于机器视觉系统来说是一个基础而重要的能力,它在移动机器人、自动驾驶、增强现实、媒体制作和内容创作等多个领域都有广泛的应用。
- 项目主页:https://rollingdepth.github.io
- GitHub:https://github.com/prs-eth/rollingdepth
- Demo:https://huggingface.co/spaces/prs-eth/rollingdepth
例如,在自动驾驶中,车辆需要理解其周围的3D环境以避免碰撞。RollingDepth能够处理视频流,为每一帧图像提供一个深度图,帮助车辆更好地理解前方的障碍物有多远。在增强现实应用中,准确的深度信息可以将虚拟对象准确地放置在现实世界中,提供更加自然和沉浸的体验。

核心技术创新
1. 多帧深度估计器
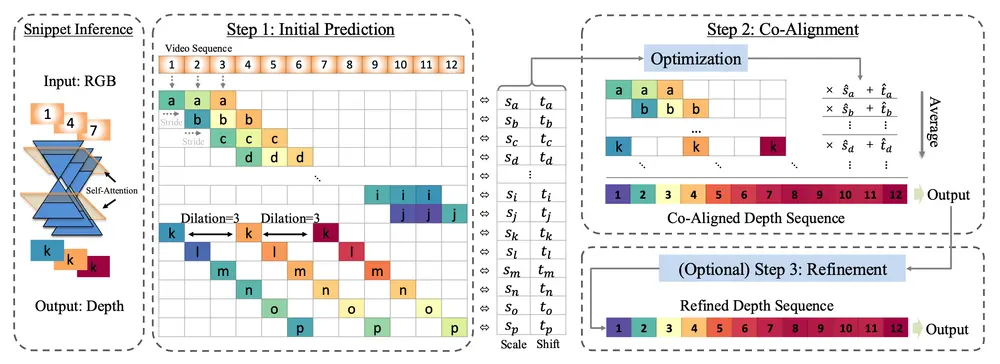
RollingDepth的第一个关键组件是一个多帧深度估计器,它源自单图像LDM。与传统的单帧方法不同,这个估计器能够处理非常短的视频片段(通常是帧三元组),并将这些片段映射到对应的深度信息。通过这种方式,RollingDepth不仅保留了单图像LDM的强大深度推断能力,还引入了时间连续性,从而减少了帧间闪烁并提高了深度估计的稳定性。
2. 基于优化的鲁棒配准算法
RollingDepth的第二个重要组成部分是一个基于优化的鲁棒配准算法。该算法能够在不同帧率下采样的深度片段之间进行最佳组装,确保生成的深度视频在时间和空间上的一致性。具体来说,配准算法通过最小化相邻深度片段之间的差异,自动调整和对齐各个片段,最终生成一个连贯且准确的深度视频。这一过程不仅提高了深度估计的精度,还能有效处理包含数百帧的长时间视频。
主要特点
- 无需视频模型:与依赖视频扩散模型的方法不同,RollingDepth扩展了单图像的潜在扩散模型(LDM),使其能够处理视频片段。
- 多帧深度估计:通过处理非常短的视频片段(通常是三个连续帧),并将其映射到深度片段。
- 全局对齐算法:通过一个鲁棒的、基于优化的全局对齐算法,将不同帧率采样的深度片段重新组合成一致的视频。
- 高效处理:能够高效处理数百帧的长视频,并提供比专门的视频深度估计器和高性能单帧模型更准确的深度视频。
工作原理
RollingDepth的工作原理包括以下几个步骤:
- 多帧深度估计:从单图像LDM派生出多帧深度估计器,处理短视频片段。
- 全局对齐:通过优化算法,将不同帧率采样的深度片段对齐到一个共同的尺度和偏移,以获得一致的视频。
- 可选的精细化处理:通过适度的随机噪声降解和再次去噪,进一步细化空间细节。
性能优势
RollingDepth在多个方面表现出色,显著优于现有的专用视频深度估计器和单帧模型:
- 时间一致性:通过多帧深度估计器和优化配准算法,RollingDepth有效地解决了传统方法中的时间连续性问题,减少了帧间闪烁。
- 深度准确性:实验结果显示,RollingDepth生成的深度视频在各种场景中都具有更高的准确性,尤其是在相机运动复杂的情况下。
- 处理效率:RollingDepth能够高效处理长时间视频,其计算复杂度远低于基于视频基础模型的方法,同时保持了高质量的深度估计。
- 适应性强:RollingDepth可以灵活应对不同帧率和分辨率的输入视频,适用于广泛的视频内容。
实验验证与应用前景
研究人员对RollingDepth进行了广泛的实验评估,结果表明,该模型在多个基准测试中均表现出色,特别是在处理长时间视频时,RollingDepth生成的深度视频质量显著优于现有方法。此外,RollingDepth在实际应用场景中也展示了巨大的潜力,包括但不限于:
- 自动驾驶:为车辆提供精确的环境感知,辅助导航和避障。
- 增强现实:实现更加逼真的虚拟物体与真实世界的融合,提升用户体验。
- 影视制作:用于电影和电视剧的特效制作,提供高质量的3D效果。
- 机器人视觉:帮助机器人更好地理解周围环境,执行复杂的任务。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











