
使用文本到图像生成模型(Text-to-Image Models)来个性化地创造图像,这些模型能够根据自然语言描述生成图像,但通常难以精确地表达特定的独特概念。
来自特拉维夫大学与英伟达的研究人员于2022年提出了一种名为“Textual Inversion”(文本反转)的方法,它允许用户通过少量的图像和自然语言描述来创建新的“伪词”(pseudo-words),这些伪词代表了特定的概念,并且可以被用来指导图像生成过程。

主要功能:
- 个性化图像生成:用户可以根据自己的概念,如一个物体或风格,生成新的图像。
- 语言引导创作:通过自然语言句子来指导图像的生成,使得创作过程更加直观。
- 概念嵌入:将用户提供的概念嵌入到预训练的文本到图像模型的嵌入空间中,形成新的伪词。
主要特点:
- 创造性自由:用户可以通过少量的图像和描述来学习并代表新的概念。
- 直观编辑:用户可以像使用普通单词一样,将这些伪词组合成句子,直观地改变图像的风格、场景或将它们融入新产品中。
- 高保真度:这种方法能够更忠实地描绘概念,并且在多种应用和任务中表现良好。
工作原理:
- 用户提供3-5张代表特定概念的图像。
- 使用这些图像作为训练集,通过优化过程找到能够代表该概念的嵌入向量(即伪词)。
- 这个嵌入向量可以被用来生成新的图像,或者与自然语言描述结合,生成具有特定风格和场景的新图像。
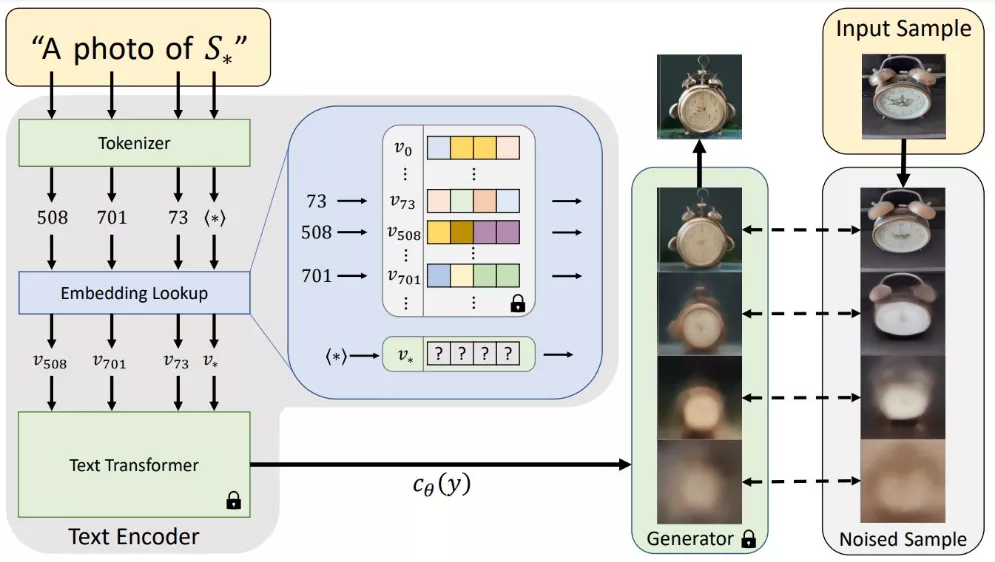
让我们通过一个具体的例子来说明这个模型是如何工作的:
假设你有一个特别喜欢的卡通角色,比如“海绵宝宝”(SpongeBob SquarePants),你想要创造一些新的图像,展示海绵宝宝在不同的场景和风格中的样子。你手头有一些海绵宝宝的图片,比如他在海底世界、在比萨店工作,或者穿着超级英雄服装的样子。
- 概念学习:首先,你将这些海绵宝宝的图片上传到模型中。模型会分析这些图片,学习海绵宝宝的特征,比如他的黄色方形身体、大眼睛和红色领带。
- 创建伪词:模型在它的嵌入空间中找到一个新的位置,这个位置代表了“海绵宝宝”这个概念。这个位置就像是一个新词,我们可以用一个特殊的符号“S*”来表示。
- 生成图像:现在,你可以用自然语言描述来指导模型生成新的海绵宝宝图像。比如,你可以输入“S在月球上”,模型就会生成一张海绵宝宝站在月球表面的图像。或者,你可以说“S穿着文艺复兴时期的服装”,模型就会创作出一张海绵宝宝穿着达芬奇时代服装的画作。
- 风格转换:如果你想要海绵宝宝的风格发生变化,比如变成印象派风格,你可以输入“S*在印象派风格中”,模型会生成一张具有印象派风格的海绵宝宝图像。
- 组合概念:你还可以组合不同的概念。比如,你可以输入“S*和派大星在海滩上钓鱼”,模型会生成一张海绵宝宝和他的好朋友派大星在海滩上钓鱼的图像。

通过这个例子,你可以看到模型如何通过学习少量的图像和自然语言描述,来理解和生成具有特定概念的图像。这种方法不仅能够创造出新的图像,还能够在不同的风格和场景中灵活地应用这些概念。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











