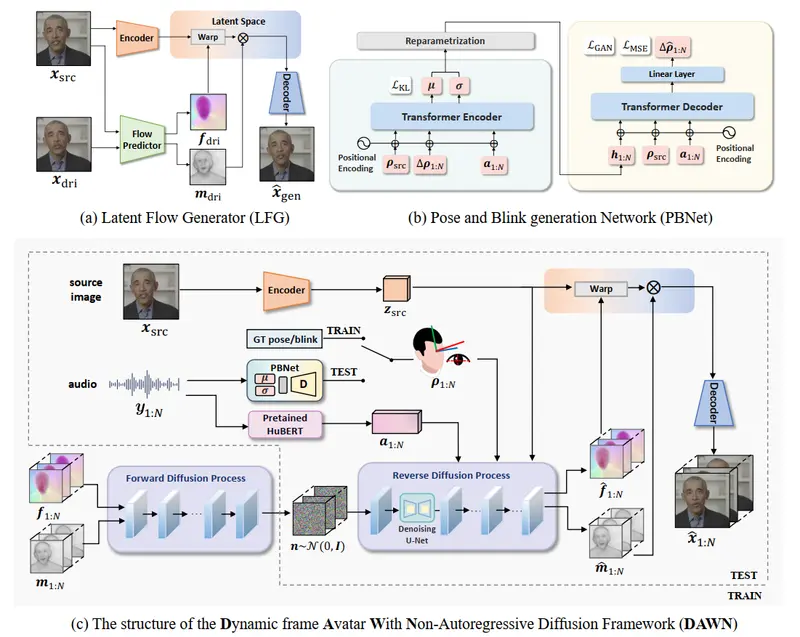
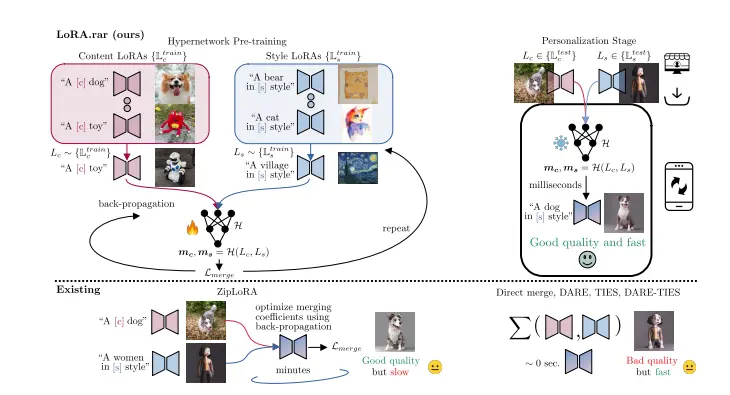
来自网易伏羲AI实验室、悉尼科技大学的研究人员推出了从单人音频生成单人说话脸部的框架Audio-Visual Correlation Transformer (AVCT),它能够从单个说话者的音频-视觉关联学习中生成逼真的说话面部视频。
这种方法特别关注于从特定说话者那里学习一致的说话风格,然后将这种风格转移到参考图像上,从而生成新的说话视频。这种方法对于数字人类动画、电影的视觉配音和快速短视频创作等应用非常重要。
主要功能:
- 生成逼真的说话面部视频,包括自然嘴型和准确的唇同步。
- 能够处理任意说话者的音频,生成与参考图像相匹配的说话视频。
主要特点:
- 一致性学习: 通过学习特定说话者的音频和视觉动作之间的关联,生成一致的说话风格。
- 泛化能力: 使用音素(phonemes)来表示音频信号,使得模型能够泛化到其他说话者。
- 关键点驱动: 使用关键点和密集运动场(dense motion fields)来表示面部动作,提高了生成视频的质量。
- 相对运动转移: 在推理阶段,通过相对运动转移模块减少训练身份和一次性参考图像之间的运动差异。
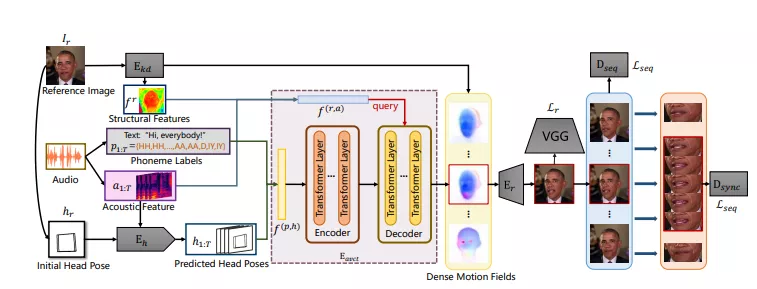
工作原理:
具体来说,该方法利用从特定说话者学习到的真实嘴唇动作和节奏性头部运动的优点,并将这些音频视觉相关性迁移到其他人身上。该方法包括四个模块:头动预测器、关键点检测器、音频视觉相关性转换器和图像渲染器。
- 头运动预测器(Head Motion Predictor):从音频中估计头部运动序列。
- 关键点检测器(Keypoint Detector):从参考图像中提取初始关键点。
- 音频-视觉关联变换器(Audio-Visual Correlation Transformer, AVCT):将音频信号映射到基于关键点的密集运动场。
- 图像渲染器(Image Renderer):从密集运动场生成输出图像。
实验结果表明,该方法可以生成具有自然嘴唇形状、同步嘴唇移动和节奏性头部运动的单人说话面部视频,并且在多个指标上优于现有的单人说话面部生成方法。
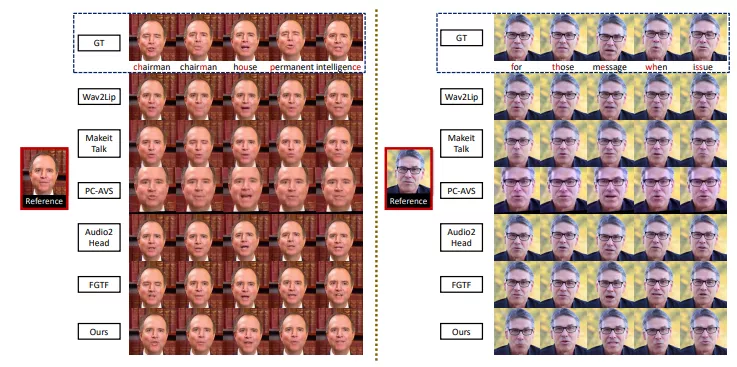
这项研究提出了一种创新的方法,能够生成高质量的说话面部视频,同时保持说话者的身份和自然的动作。这对于需要逼真面部动画的多种应用场景具有重要意义。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











