
这篇论文介绍了一个名为VSP-LLM(Visual Speech Processing incorporated with LLMs)的新框架,它结合了视觉语音处理和大语言模型(LLMs),以提高视觉语音识别(VSR)和视觉语音翻译(VST)的效率和上下文感知能力。这个框架的目标是解决视觉语音处理中的一个关键挑战:区分同音异义词(homophenes),即那些在视觉上有相同唇部动作但发音不同的单词。
此框架的作用,简单来说就是识别唇语,通过观察人的口型、面部表情和手势等视觉信息来理解他们正在说的内容。这种技术在很多场合都非常有用,比如电影字幕生成、聋哑人士辅助交流、远程会议等。然而,由于口型运动的模糊性,准确地理解视觉语音一直是一个挑战。例如,有些单词的口型运动很相似,但发音却完全不同,这时候就需要借助上下文信息来进行区分。
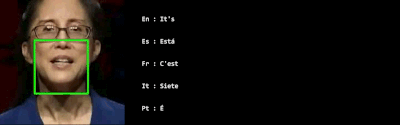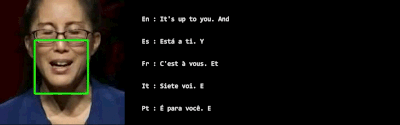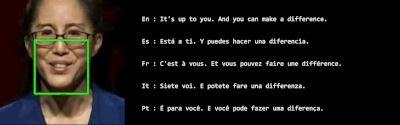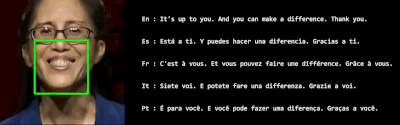
VSP-LLM是基于AV-HuBERT模型代码的基础上开发的,AV-HuBERT是Facebook开发的一个自监督的视觉语音模型,能够从视频中学习语音表示,尤其是从人的唇动中识别语音信息。这意味着VSP-LLM利用了AV-HuBERT在视觉语音识别方面的先进技术,作为其视觉语音处理组件的基础。VSP-LLM通过结合视觉语音处理和LLMs,提供了一个高效且上下文感知的解决方案,用于处理视觉语音识别和翻译任务。
主要功能和特点包括:
- 上下文建模能力:VSP-LLM利用LLMs的强大上下文建模能力,可以更准确地处理同音异义词。
- 多任务处理:VSP-LLM能够执行VSR和VST任务,通过输入指令控制任务类型。
- 计算效率:通过提出一种新颖的去重方法,减少了输入序列长度,提高了训练效率。
- 数据需求少:即使只有15小时的标记数据,VSP-LLM也能在MuAViC基准测试中实现有效的唇部动作识别和翻译。
工作原理:
- 视觉到文本空间映射:VSP-LLM使用自监督的视觉语音模型将输入视频映射到LLM的输入潜在空间。
- 视觉语音单元去重:为了减少连续帧中的冗余信息,VSP-LLM提出了一种基于视觉语音单元的去重方法,通过视觉语音单元来减少输入序列长度。
- 指令嵌入:VSP-LLM使用指令嵌入组件作为任务指定器,根据输入指令执行VSR或VST任务。
具体应用场景:
VSP-LLM可以用于电影字幕生成,帮助观众更好地理解电影中的对话内容。此外,VSP-LLM还可以用于聋哑人士辅助交流,让他们能够通过观察其他人的口型和面部表情来理解他们的意思。在远程会议中,VSP-LLM也可以帮助参会者更好地理解其他人的发言内容,提高沟通效率。
- 辅助听力受损人士:VSP-LLM可以用于开发辅助设备,帮助听力受损的人士理解视频中的对话。
- 多语言翻译:在多语言环境中,VSP-LLM可以实时翻译不同语言的唇部动作,促进跨语言交流。
- 安全监控:在安全监控领域,VSP-LLM可以用于分析监控视频中的对话内容,提高监控效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











