
清华大学和阿里巴巴的研究人员推出新型大型多模态模型ConvLLaVA,它专门设计用于处理高分辨率的视觉数据。多模态模型能够理解和处理多种类型的数据,比如文本、图像和视频,这使得它们在各种应用场景中都非常有用,比如图像和视频理解、数字代理开发以及机器人技术等。
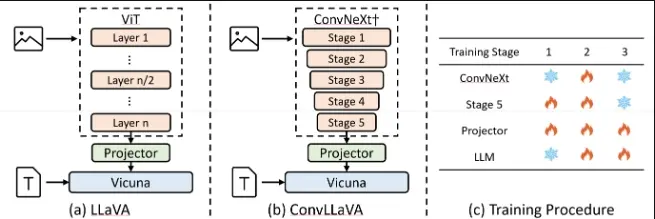
ConvLLaVA采用层次化的主干网络ConvNeXt作为LMM的视觉编码器,以替代Vision Transformer(ViT)。ConvLLaVA将高分辨率图像压缩成富含信息的视觉特征,有效避免了生成过多的视觉token。 为了增强ConvLLaVA的能力,开发人员提出了两项关键优化措施。
- 由于低分辨率预训练的ConvNeXt在直接应用于高分辨率时表现不佳,我们更新它以弥合这一差距。
- 此外,由于ConvNeXt原有的压缩比对于更高分辨率的输入来说不足,我们训练了一个新的stage,以进一步压缩视觉token,有效减少冗余。
这些优化使得ConvLLaVA能够支持1536x1536分辨率的输入,同时仅生成576个视觉token,并适应任意宽高比的图像。
主要功能和特点:
- 高分辨率视觉编码:ConvLLaVA使用了一个名为ConvNeXt的分层背骨(hierarchical backbone)作为视觉编码器,替代了传统的Vision Transformer(ViT)。这种设计使得模型能够处理高达1536×1536分辨率的图像,同时生成的信息丰富的视觉特征(visual tokens)数量较少,减少了计算负担。
- 减少视觉冗余:通过压缩高分辨率图像到信息丰富的视觉特征,ConvLLaVA有效地避免了生成过多的视觉tokens,这一点与传统的ViT相比是一个显著的改进,因为ViT会产生大量的视觉tokens,导致计算成本大幅增加。
- 关键优化:为了提高性能,论文提出了两个重要的优化措施。首先,针对ConvNeXt在高分辨率下性能不佳的问题,作者通过更新模型以弥补这一差距。其次,为了解决原始ConvNeXt压缩比率不足以处理更高分辨率输入的问题,作者训练了一个额外的阶段来进一步压缩视觉tokens,从而减少冗余。
- 任意纵横比支持:由于卷积的平移等价性,ConvLLaVA能够处理任意纵横比的图像,这增加了模型的灵活性。
工作原理:
ConvLLaVA的工作原理主要基于以下几个步骤:
- 分层视觉编码:使用ConvNeXt作为视觉编码器,通过分层的方式逐步压缩视觉特征。
- 特征压缩:通过增加额外的ConvNeXt阶段,进一步压缩视觉信息,从而减少视觉tokens的数量。
- 端到端训练:模型通过三个训练阶段进行端到端优化,包括视觉编码器的更新、视觉-语言预训练以及视觉指令调整。
具体应用场景:
- 图像和视频理解:在需要模型理解复杂场景和执行多种任务的应用中,比如视频分析或图像识别。
- 数字代理开发:在创建能够与用户交互并理解视觉内容的虚拟助手或数字代理时。
- 机器人技术:在需要机器人理解周围环境的视觉信息并做出决策的场景中。
- 文档图像处理:在需要从文档图像中提取和理解文本信息的场景中,比如自动化文档分析或OCR(光学字符识别)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











