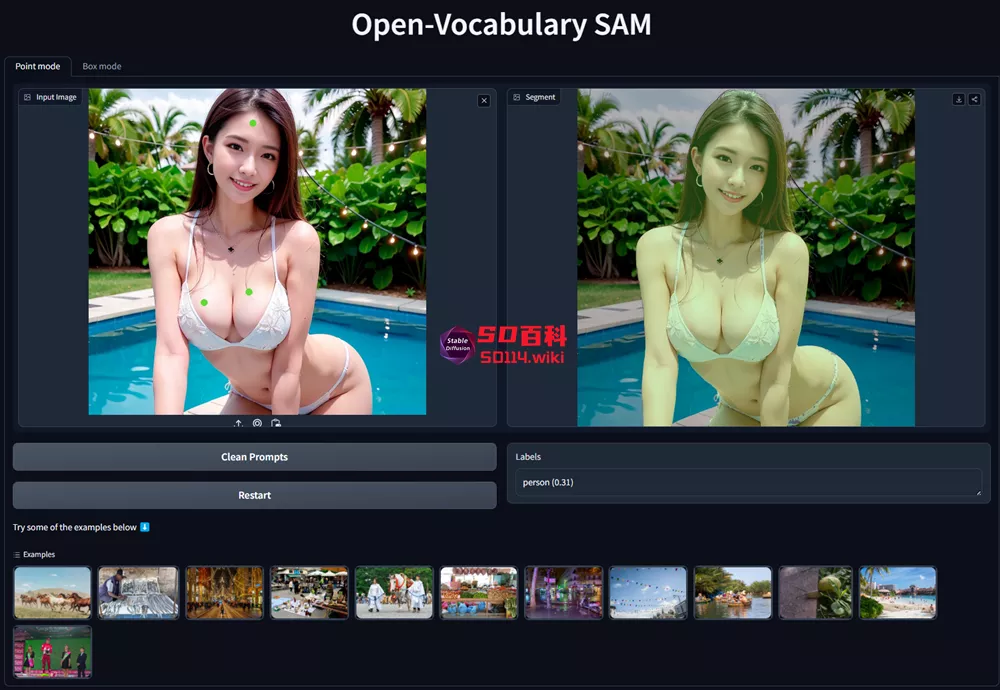
来自南洋理工大学、上海AI实验室的研究人员推出了一款基于SAM的新型视觉模型Open-Vocabulary SAM,它结合了Segment Anything Model(SAM)和CLIP模型的优势,旨在实现交互式的图像分割和识别。
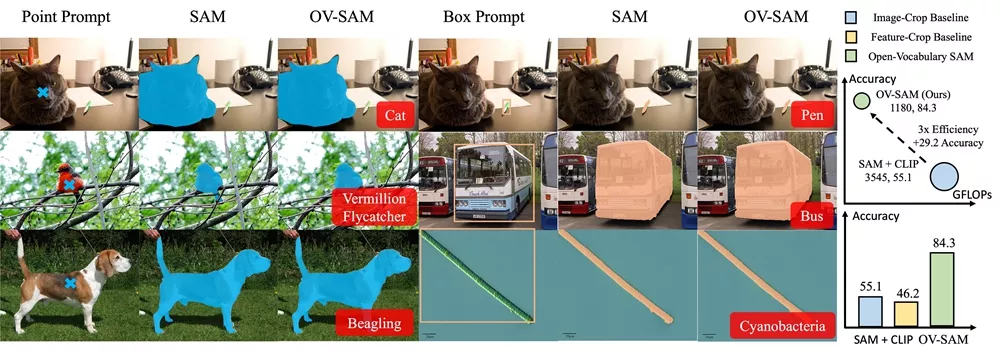
SAM擅长于分割任务,而CLIP则以其零样本(zero-shot)识别能力著称。OV-SAM通过两个独特的知识转移模块——SAM2CLIP和CLIP2SAM,将这两种模型的能力结合起来,使得它能够在识别图像中的物体的同时,还能对它们进行精确的分割。
主要特点:
- 交互式分割与识别:OV-SAM能够根据用户的输入(如点击或拖动框)来分割和识别图像中的物体。
- 知识转移:通过SAM2CLIP模块,OV-SAM将SAM的知识转移到CLIP中,而CLIP2SAM模块则将CLIP的知识转移到SAM中,从而提高了模型的识别能力。
- 开放词汇能力:OV-SAM能够处理大约22,000个类别的物体,这意味着它能够识别和分割大量未见过的物体。
- 计算效率:与简单的SAM和CLIP结合方法相比,OV-SAM在保持高性能的同时,显著减少了计算成本。

工作原理:
OV-SAM的工作原理可以分为以下几个步骤:
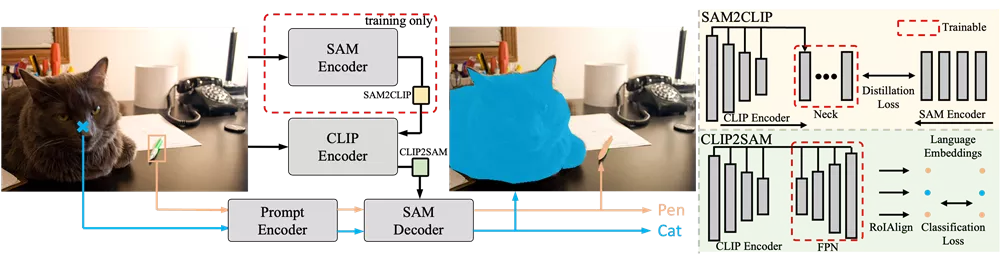
- SAM2CLIP:首先,使用SAM作为教师网络,通过蒸馏(distillation)过程将SAM的知识转移到CLIP的视觉编码器中。这个过程通过一个轻量级的变换器适配器(adapter)来实现,适配器接收多尺度特征并尝试将CLIP的特征与SAM的特征对齐。
- CLIP2SAM:然后,CLIP2SAM模块将CLIP的知识转移到SAM的解码器中,这个模块包括一个特征金字塔网络(FPN),用于提取多尺度CLIP特征,并与SAM的解码器联合训练,以实现精确的分割和分类。
- 训练与推理:在训练阶段,OV-SAM使用SAM数据进行初步训练,然后结合COCO或LVIS数据集进行联合训练。在推理阶段,OV-SAM能够根据用户的交互式提示(如点击或拖动框)来生成分割掩模和识别标签。
应用场景:
- 图像编辑:OV-SAM可以帮助用户在图像编辑软件中快速选择和编辑特定区域,例如,用户可以通过点击来选择图像中的某个物体,然后进行裁剪或调整。
- 自动标注工具:在数据标注过程中,OV-SAM可以自动识别和分割图像中的物体,大大加快了标注速度,提高了标注的准确性。
- 增强现实(AR)和虚拟现实(VR):在AR和VR应用中,OV-SAM可以用来识别和分割现实世界中的物体,为用户提供更丰富的交互体验。
- 内容创作:艺术家和设计师可以利用OV-SAM来创建复杂的场景,通过交互式分割来精确控制图像元素,实现创意设计。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











