IDEA 研究院是由沈向洋创立,他们在2021年11月22日宣布启动“封神榜”大模型开源体系。“封神榜”是由 IDEA-CCNL 的工程师、研究人员、实习生团队共同维护的一项长期开源计划。项目基于Apache 2.0开源许可,计划包括封神榜模型,封神框架还有封神榜单三个部分。
近期它们发布了双语文本到图像生成模型Taiyi-Diffusion-XL,这个模型通过扩展CLIP和Stable-Diffusion-XL的能力,来实现支持中文提示词。
该模型特点:
- 高效算法:开发了针对双语上下文的文本到图像模型的词汇扩展和位置编码算法,以实现更准确和文化敏感的图像生成。
- 文本提示丰富:利用大型视觉-语言模型来丰富文本提示,显著提升了模型理解和可视化复杂文本描述的能力。
- 双语模型创建:利用多模态基础模型的能力,开发并开源了Taiyi-XL模型,这在双语文本到图像模型的研究和应用方面是一个显著的进步。

官方介绍:
文生图模型如谷歌的Imagen、OpenAI的DALL-E 3和Stability AI的Stable Diffusion引领了AIGC和数字艺术创作的新浪潮。然而,基于SD v1.5的中文文生图模型,如Taiyi-Diffusion-v0.1和Alt-Diffusion的效果仍然一般。
中国的许多AI绘画平台仅支持英文,或依赖中译英的翻译工具。目前的开源文生图模型主要支持英文,双语支持有限。我们的工作,Taiyi-Diffusion-XL(Taiyi-XL),在这些发展的基础上,专注于保留英文理解能力的同时增强中文文生图生成能力,更好地支持双语文生图。
模型训练
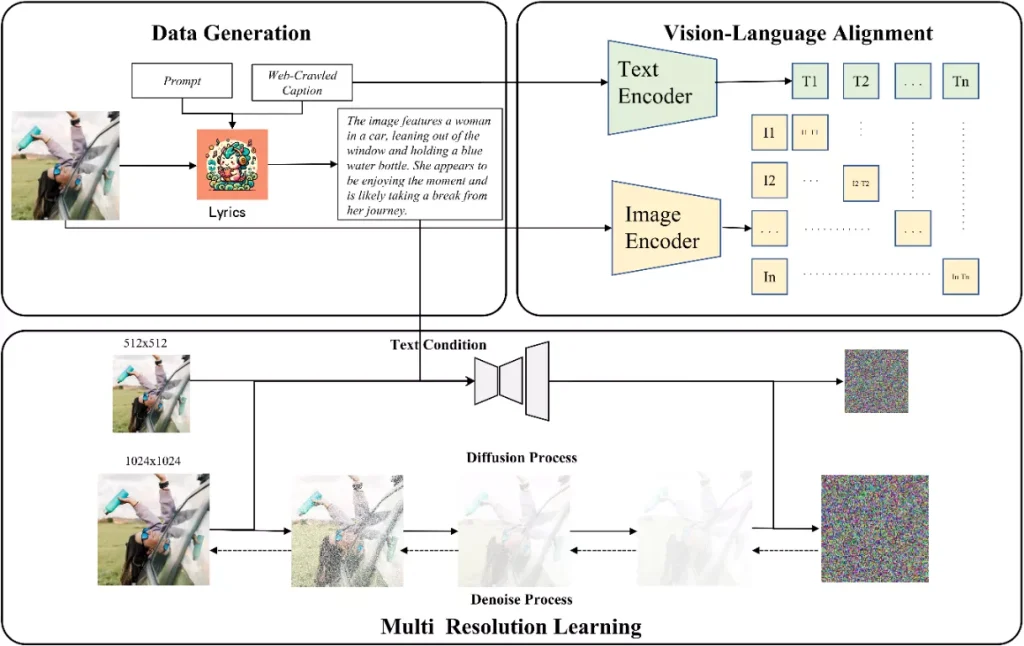
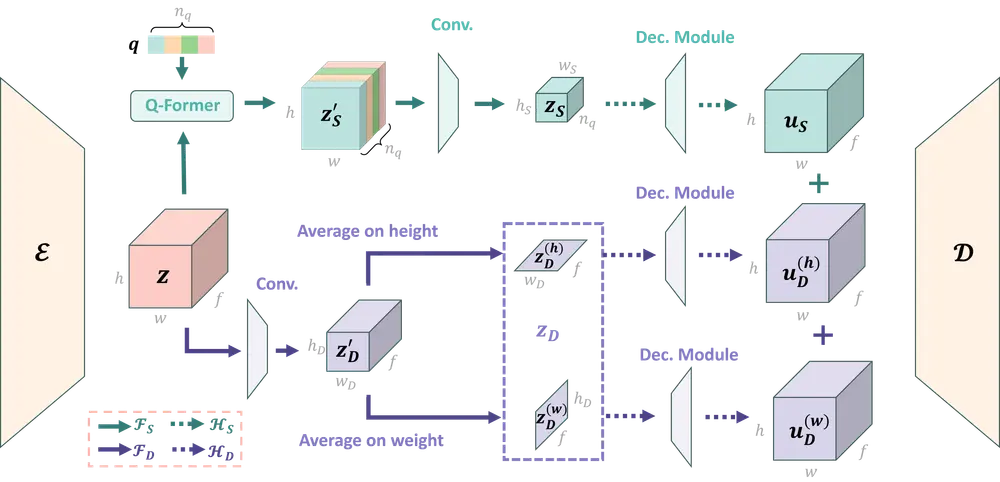
Taiyi-Diffusion-XL文生图模型训练主要包括了3个阶段:
首先,我们制作了一个高质量的图文对数据集,每张图片都配有详细的描述性文本。为了克服网络爬取数据的局限性,我们使用先进的视觉-语言大模型生成准确描述图片的caption。这种方法丰富了我们的数据集,确保了相关性和细节。
然后,我们从预训练的英文CLIP模型开始,为了更好地支持中文和长文本我们扩展了模型的词表和位置编码,通过大规模双语数据集扩展其双语能力。训练涉及对比损失函数和内存高效的方法。
最后,我们基于Stable-Diffusion-XL,替换了第二阶段获得的text encoder,在第一阶段获得的数据集上进行扩散模型的多分辨率、多宽高比训练。
机器评估
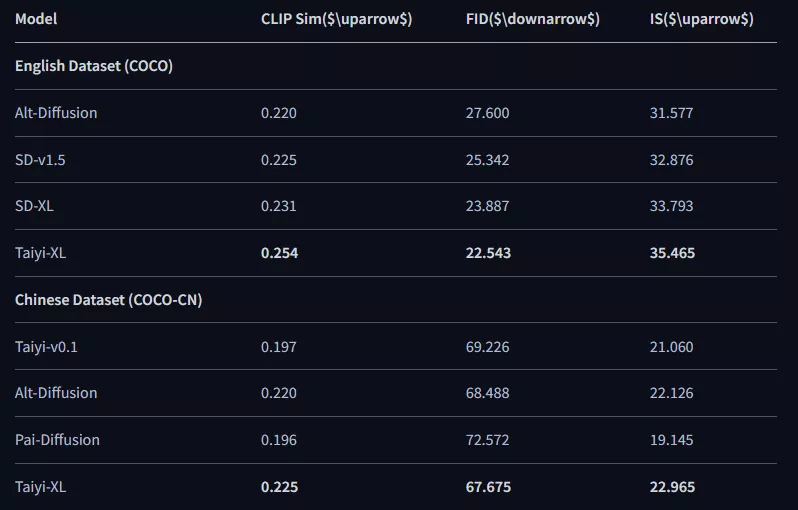
我们的机器评估包括了对不同模型的全面比较。评估指标包括CLIP相似度(CLIP Sim)、IS和FID,为每个模型在图像质量、多样性和与文本描述的对齐方面提供了全面的评估。在英文数据集(COCO)中,Taiyi-XL在所有指标上表现优异,获得了最好的CLIP Sim、IS和FID得分。
这表明Taiyi-XL在生成与英文文本提示紧密对齐的图像方面非常有效,同时保持了高图像质量和多样性。同样,在中文数据集(COCO-CN)中,Taiyi-XL也超越了其他模型,展现了其强大的双语能力。
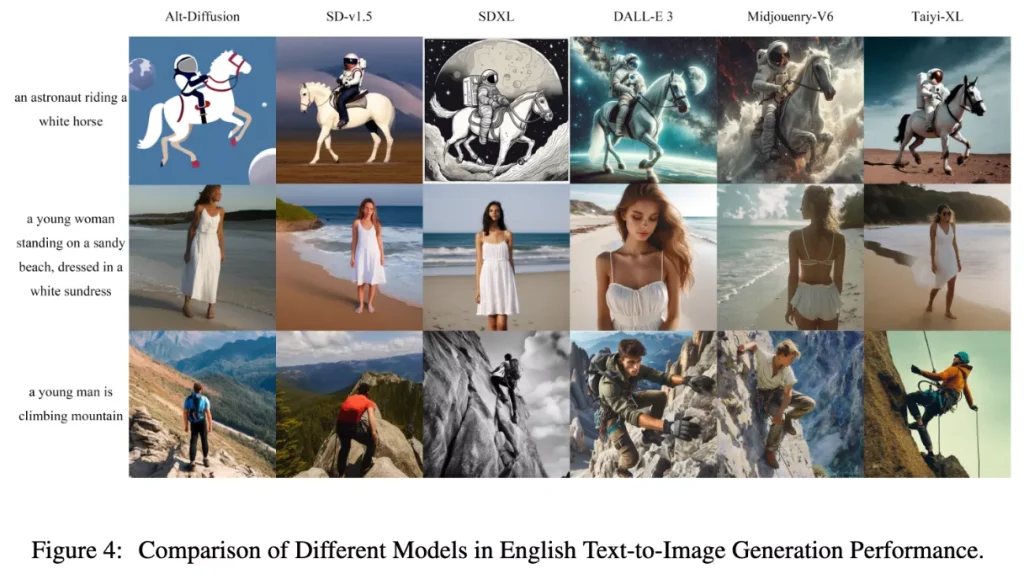
人类偏好评估
如下图所示,比较了不同模型在中英文文生图生成方面的表现:
- XL版本模型,如SD-XL和Taiyi-XL,在1.5版本模型如SD-v1.5和Alt-Diffusion上显示出显著改进。
- DALL-E 3以其生动的色彩和prompt-following的能力而著称。
- Taiyi-XL模型偏向生成摄影风格的图片,与Midjourney较为类似,但是Taiyi-XL并在双语(中英文)文生图生成方面表现更出色。

尽管Taiyi-XL可能还未能与商业模型相媲美,但它比当前双语开源模型优越不少。我们认为我们模型与商业模型的差距主要归因于训练数据的数量、质量和多样性的差异。
我们的模型仅使用学术数据集和符合版权要求的图文数据进行训练,未使用Midjourney和DALL-E 3等生成数据。正如大家所知的,版权问题仍然是文生图和AIGC模型最大的问题。当然由于数据限制,对于中国人像或者元素我们也希望开源社区进一步数据微调。
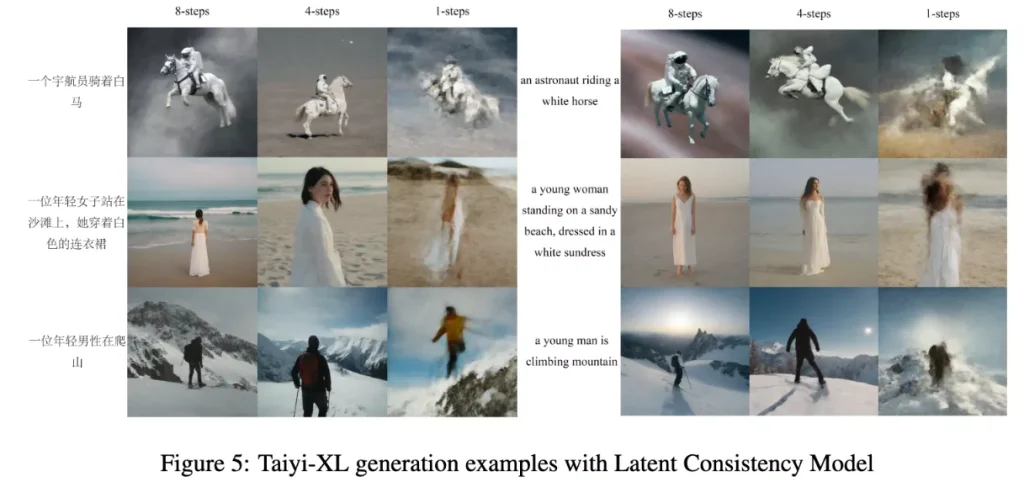
我们还评估了使用潜在一致性模型(LCM)加速图像生成过程的影响。测试显示,推理步骤减少,图像质量下降。生成过程扩展到8步基本可以确保生成图像的质量;生成过程限制为1步时,生成的图像主要只展示了基本轮廓,缺乏更细致的细节。这一发现表明,LCM可以有效加速生成过程,但在步数和所需图像质量之间需要找到平衡。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











