
中佛罗里达大学计算机视觉研究中心和字节跳动的研究人员推出ControlNet++,这是一种新方法,通过显式优化生成图像与条件控制之间的像素级循环一致性,来改进可控生成过程。具体来说,对于给定的条件控制,我们使用一个预训练的判别式奖励模型来提取生成图像的相应条件,并随后优化输入条件控制与提取条件之间的一致性损失。
- 项目主页:https://liming-ai.github.io/ControlNet_Plus_Plus
- 论文地址:https://arxiv.org/abs/2404.07987
- Demo:https://huggingface.co/spaces/limingcv/ControlNet-Plus-Plus
一种直接的实现方式是从随机噪声中生成图像,并计算一致性损失,但这种方法需要存储多个采样时间步的梯度,导致时间和内存成本显著增加。为了解决这个问题,开发团队提出了一种高效的奖励策略,通过添加噪声故意干扰输入图像,然后利用单步去噪图像进行奖励微调。这种方法避免了与图像采样相关的巨大成本,使得奖励微调更加高效。

通过大量的实验,开发团队发现ControlNet++在各种条件控制下都显著提高了可控性。例如,在分割掩码、线条边缘和深度条件方面,ControlNet++分别比ControlNet提高了7.9%的mIoU、13.4%的SSIM和7.6%的RMSE。这些结果充分证明了ControlNet++在提升文本到图像扩散模型可控性方面的有效性。
主要功能和特点:
- 提高图像生成的可控性:ControlNet++通过优化生成图像与视觉条件之间的像素级循环一致性,提高了模型生成图像的准确性。
- 有效的一致性反馈:使用预训练的判别性奖励模型作为视觉奖励模型,以循环一致性的方式提高可控性。
- 高效的奖励微调策略:通过向输入图像添加噪声并使用单步去噪图像进行奖励微调,避免了从随机噪声采样图像所带来的时间和内存开销。
工作原理:
ControlNet++将基于图像的可控生成视为图像翻译任务,从输入条件控制到输出生成图像。它受到CycleGAN的启发,使用预训练的判别性模型从生成的图像中提取条件,并直接优化循环一致性损失以获得更好的可控性。循环一致性是指,如果我们将图像从一个域(条件cv)翻译到另一个域(生成图像x'0),然后再翻译回来(生成图像x'0到条件c'v),我们应该回到起点(c'v = cv)。例如,给定一个分割掩码作为条件控制,可以使用ControlNet等现有方法生成相应的图像。然后,这些生成图像的预测分割掩码可以通过预训练的分割模型获得。理想情况下,预测的分割掩码和输入的分割掩码应该是一致的。
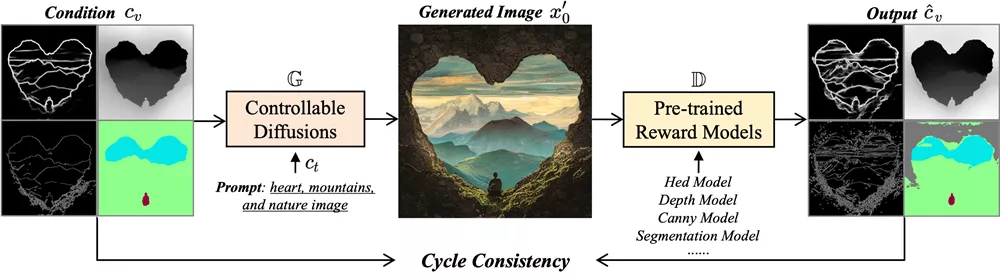
具体应用场景:
- 文本到图像的生成:用户可以输入文本描述,模型根据描述生成相应的图像,并可以通过额外的视觉条件控制生成的图像内容。
- 图像编辑:在图像编辑任务中,可以通过控制条件(如分割掩码)来精确修改图像的特定区域。
- 艺术创作:艺术家和设计师可以使用ControlNet++来创作符合特定视觉风格或主题的艺术作品。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











