
天工 AI、南洋理工大学和新加坡国立大学的研究人员提出了MEMO(Memory-Guided Emotion-Aware Diffusion),这是一种端到端的音频驱动肖像动画方法,旨在生成身份一致且富有表现力的说话视频。MEMO通过引入两个关键模块——记忆引导的时间模块和情绪感知的音频模块,解决了无缝音频-唇同步、长期身份一致性和自然的音频对齐表情等重大挑战。
- 项目主页:https://memoavatar.github.io
- GitHub:https://github.com/memoavatar/memo
- 模型:https://huggingface.co/memoavatar/memo
- ComfyUI插件:https://github.com/if-ai/ComfyUI-IF_MemoAvatar
例如,我们有一张某人的参考图片和一段包含特定情感色彩的音频。使用MEMO,我们可以生成一个视频,视频中的人物不仅能够准确地与音频同步唇动,还能展现出与音频情感相匹配的面部表情。例如,如果音频是快乐的,视频中的人物会展现出快乐的表情;如果音频是悲伤的,视频中的人物表情也会相应地变得悲伤。

主要功能和特点
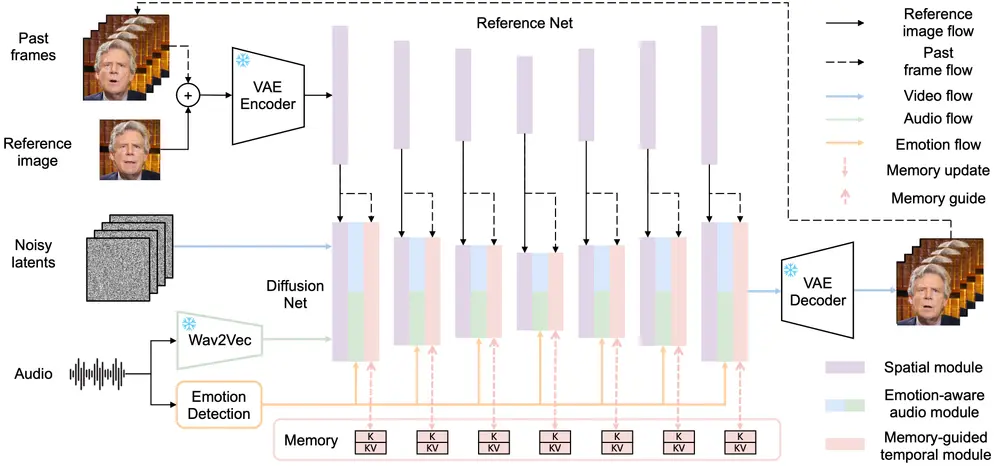
- 记忆引导的时间模块:通过维护长期记忆状态来存储更早之前生成帧的信息,以指导时间建模,从而增强长期身份一致性和运动平滑性。
- 情感感知的音频模块:替换传统的交叉注意力机制,使用多模态注意力机制来增强音频和视频之间的交互,并从音频中动态检测情感,以细化面部表情。
- 无需面部归纳偏差:MEMO不依赖于任何面部归纳偏差,这使得它可以生成更具表现力的头部运动。
- 提高音频-唇动同步和表情-情感对齐:MEMO能够生成与输入音频情感色调相匹配的自然表情,提高音频-唇动同步的准确性。
工作原理
MEMO的工作原理基于以下几个关键步骤:
- 记忆引导的时间模块:使用线性注意力机制和记忆更新机制来处理长期时间信息,从而在视频生成过程中提供更全面的时间指导。
- 情感感知的音频模块:通过多模态注意力机制和情感自适应层归一化(Emo-AdaNorm),将音频情感信息整合到视频生成过程中,以生成更具表现力的视频。
- 数据预处理管道:通过一系列步骤(场景转换检测、人脸检测、图像质量评估、音频-唇动同步检测等)来处理原始视频数据,以获取高质量的谈话头视频。
- 训练策略分解:MEMO的训练分为两个阶段,首先是面部领域适应,然后是情感解耦的鲁棒训练,以优化扩散模型的训练。
实验结果与性能提升
广泛的定量和定性实验结果表明,MEMO在各种图像和音频类型中生成了更逼真的说话视频,尤其在以下几个方面表现出色:
- 整体质量:MEMO生成的视频在视觉质量和细节表现上显著优于现有方法,能够准确反映输入音频的内容和情感。
- 音频-唇同步:MEMO在音频-唇同步方面表现出色,生成的嘴唇运动与音频内容高度一致,避免了常见的不同步现象。
- 身份一致性:通过记忆引导的时间模块,MEMO能够在长时间的视频生成中保持身份一致性,确保生成的视频不会出现身份漂移的问题。
- 表情-情绪对齐:情绪感知的音频模块使得MEMO生成的面部表情与音频内容的情感高度对齐,增强了视频的真实感和表现力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











