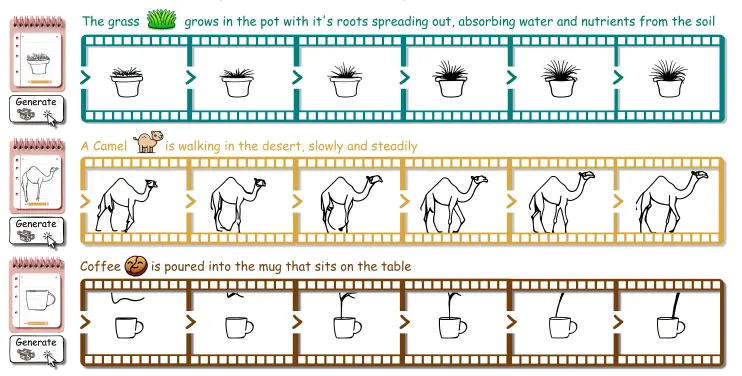
Meta和耶路撒冷希伯来大学的研究人员推出图生视频框架Through-The-Mask,旨在将静态图像转换为基于文本描述的真实视频序列。该框架通过引入基于掩码的运动轨迹作为中间表示,能够准确地动画化多个对象,生成具有连贯和真实运动的视频。例如,给定一张静态图像和描述“一只卡通超级英雄抬起右腿,双手合十仿佛在祈祷”,Through-The-Mask可以生成一个视频,其中超级英雄按照描述进行动作。

主要功能
- 多对象动画化:能够处理包含多个对象的图像,并为每个对象生成准确的运动轨迹,确保视频中对象的运动连贯且符合文本描述。
- 高保真视频生成:生成的视频不仅在视觉上逼真,而且在时间上连贯,能够忠实地反映输入图像和文本提示的内容。
- 灵活的运动控制:通过掩码和注意力机制,可以对视频中的对象运动进行精细控制,实现复杂的运动效果和对象交互。
主要特点
- 两阶段生成框架:将I2V生成分解为两个阶段:首先是生成基于掩码的运动轨迹,其次是基于该轨迹生成视频。这种分解方法使得模型能够更好地处理对象的语义和运动。
- 掩码基础的运动轨迹:作为一种中间表示,掩码基础的运动轨迹不仅捕捉对象的运动,还包含语义信息,使得生成的视频在对象级别上更加准确和连贯。
- 注意力机制:通过掩码交叉注意力和掩码自注意力机制,确保生成的视频在对象级别上保持一致性和连贯性,同时忠实地反映文本提示的内容。
工作原理
Through-The-Mask的工作流程主要包括以下几个步骤:
- 数据预处理:从输入文本中提取运动相关的对象提示,使用Grounding DINO生成每个对象的边界框,并使用SAM2创建视频分割。同时,从输入文本中提取运动特定提示和对象特定提示。
- 图像到运动生成:训练一个模型,根据输入图像、分割掩码和运动特定提示生成基于掩码的运动轨迹。这些轨迹捕捉了每个对象的动态行为。
- 运动到视频生成:训练另一个模型,根据输入图像、生成的运动轨迹、文本提示和对象特定提示生成最终的视频。通过掩码注意力机制,确保生成的视频在对象级别上保持一致性和连贯性。
- 掩码注意力机制:引入掩码交叉注意力和掩码自注意力机制,确保每个对象的潜在表示只关注其自身的提示,并在时间上保持一致性。
具体应用场景
- 数字内容创作:在动画制作、影视特效制作等领域,创作者可以利用该方法快速将静态图像转化为动态视频,减少手工绘制或制作动画的工作量,提高创作效率。例如,在制作一部动画短片时,艺术家可以通过绘制关键帧图像并提供相应的文本描述,使用该模型生成中间帧,从而加速动画制作过程,同时保持较高的质量和连贯性。
- 虚拟现实(VR)与增强现实(AR):为 VR 和 AR 应用提供丰富的动态内容。在 VR 场景中,可以根据用户的交互或场景需求,将静态的虚拟物体图像转换为动态的视频序列,增强虚拟环境的沉浸感;在 AR 应用中,对现实场景中的图像进行动态增强,如为一幅建筑图像添加动态的光影效果或人物活动,使 AR 体验更加生动有趣。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











