
随着对沉浸式 AR/VR 应用和空间智能需求的增加,生成高质量的场景级和 360° 全景视频变得尤为重要。然而,大多数视频扩散模型受限于分辨率和宽高比,限制了它们在场景级动态内容合成中的应用。为了解决这些挑战,州大学默塞德分校、谷歌 DeepMind 和华南理工大学的研究人员提出了 DynamicScaler,这是一个通过实现空间可扩展和全景动态场景合成的创新框架。它用于生成高质量、可扩展的全景动态场景视频。DynamicScaler能够根据图像和文本条件,或者仅根据文本来生成动态全景图,提供沉浸式的视觉效果,适用于AR/VR应用和各种尺寸的显示设备。
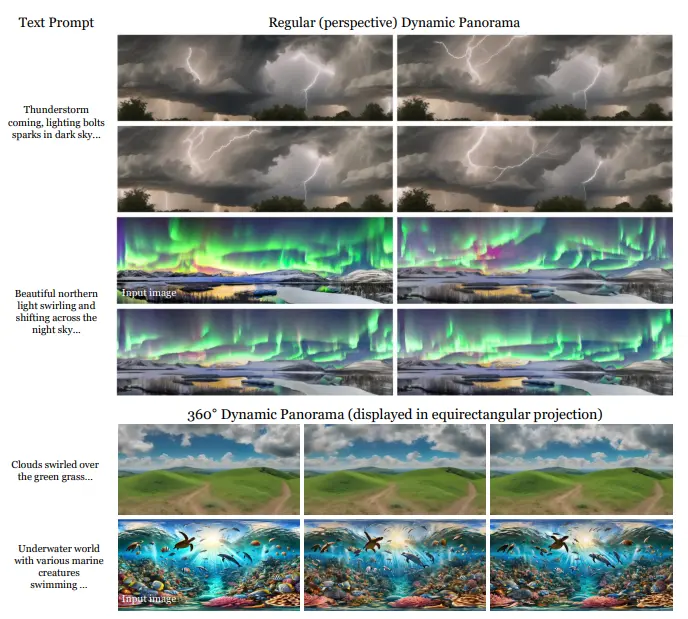
例如,我们有一段描述“暴风雨来临,闪电在暗色天空中闪烁”的文本,DynamicScaler可以根据这段描述生成一个动态的全景视频,展示暴风雨和闪电的景象。或者,我们有一张特定角度的输入图像,DynamicScaler可以生成一个360度的动态全景视图,让用户能够体验到全方位的场景。
主要贡献
偏移移位去噪器(Offset-Shifted Denoiser):
- 功能:通过固定分辨率的扩散模型,借助无缝旋转窗口,实现高效、同步和一致的全景动态场景去噪。
- 优势:确保无缝边界过渡和整个全景空间的一致性,适应不同的分辨率和宽高比,解决了传统方法在处理大尺寸全景场景时的局限性。
全局运动引导机制(Global Motion Guidance Mechanism):
- 功能:确保局部细节保真度和全局运动连续性。
- 优势:通过全局运动引导,DynamicScaler 能够在生成过程中保持一致的运动轨迹,避免了局部细节失真和运动不连贯的问题。
VRAM 消耗恒定:
- 功能:无论输出视频分辨率如何,VRAM 消耗保持恒定。
- 优势:这一特性使得 DynamicScaler 可以在不同硬件配置上高效运行,降低了对高端硬件的需求,提升了模型的可扩展性和适用性。
方法概述
DynamicScaler 的管道分为两个主要阶段:
低分辨率阶段:
- 360° 设置(黄色块):涉及全景投影去噪,以初始化适合球形全景的运动。通过无缝旋转窗口,DynamicScaler 在固定分辨率下进行高效的全景去噪,确保了全景视频的空间一致性。
- 常规透视设置(蓝色块):在早期去噪步骤中使用带重叠的偏移移位,然后由偏移移位去噪器完成剩余的去噪步骤。这一阶段建立了粗略的运动结构,为后续的高分辨率生成奠定了基础。
上采样阶段(绿色块):
- 功能:利用更多移位窗口,结合低分辨率视频的全局运动引导,生成精细的高分辨率全景。通过多尺度的去噪和上采样,DynamicScaler 能够生成高质量的全景视频,同时保持运动的一致性和细节的保真度。
应用场景
DynamicScaler 在多个应用场景中展示了其卓越的性能:
- 循环和长视频:DynamicScaler 可以生成无限循环的视频,无缝连接到第一帧,使视频呈现为连续循环。每个循环持续 8 秒(64 帧),比基础模型时长长 4 倍,适用于需要长时间连续播放的沉浸式内容。
- 360° 全景 T2V(文本到视频):通过文本条件生成 360° 全景视频,DynamicScaler 在文本对齐方面表现出色,能够根据用户输入的文本生成符合预期的动态场景。
- 360° 全景 I2V(图像到视频):通过图像条件生成 360° 全景视频,DynamicScaler 生成的视频具有更自然和充分的运动,适用于从静态图像创建动态全景内容。
- 常规(透视)全景 T2V 和 I2V:DynamicScaler 也支持常规透视视角的全景视频生成,适用于各种视觉内容创作需求。
实验结果
大量实验表明,DynamicScaler 在全景场景级视频生成中实现了卓越的内容和运动质量。具体来说:
- T2V 比较:与 360DVD 进行了文本条件 360° 全景视频生成的比较。结果显示,DynamicScaler 在文本对齐方面优于之前的方法,生成的视频更符合用户的文本描述。
- I2V 比较:与 4K4DGen 进行了图像到 360° 全景视频生成的比较。输入图像及其结果来自 4K4DGen 的项目页面。结果显示,DynamicScaler 生成的视频具有更自然和充分的运动,尤其是在处理复杂场景时表现更为出色。
无缝性:将生成的全景视频水平拼接,展示了 DynamicScaler 的平滑边界过渡。这对于沉浸式全景内容至关重要,确保了观众在观看过程中不会注意到任何明显的拼接痕迹。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











