
视频换脸技术近年来在各种应用中变得越来越流行,但现有方法主要集中在静态图像上,难以应对视频换脸中的时间一致性和复杂场景问题。为了解决这些问题,香港中文大学 MMLab、商汤科技研究院和 InnoHK 的研究人员提出了 VividFace,这是首个专门为视频换脸设计的基于扩散模型的框架。该框架通过结合静态图像数据和时间视频序列,解决了视频人脸交换中的时序一致性、复杂场景处理等挑战,提供了一个高保真度的视频人脸交换解决方案。
例如,我们有一段视频中的人物A,我们希望将A的脸部替换成人物B的脸部,同时保持视频中A的面部表情和姿态。VividFace能够利用人物B的静态图像和视频序列,通过扩散模型生成一个新视频,其中人物A的脸部被替换为B的脸部,同时保持原有的表情和动作的连贯性。

主要挑战
时间一致性:视频换脸需要确保生成的每一帧在时间上保持一致,避免闪烁和其他不自然的现象。 身份保留:在换脸过程中,必须确保目标人脸的身份特征(如面部结构)得到准确保留。 姿态和遮挡鲁棒性:处理大幅度的姿态变化和部分遮挡是视频换脸中的关键挑战。
方法概述
VividFace 通过引入一种新颖的 图像-视频混合训练框架 和 属性-身份解耦三元组(AIDT)数据集,解决了上述挑战。该框架结合了专门设计的扩散模型和 VidFaceVAE,能够有效处理静态图像和时间视频序列,从而更好地保持生成视频的时间一致性。
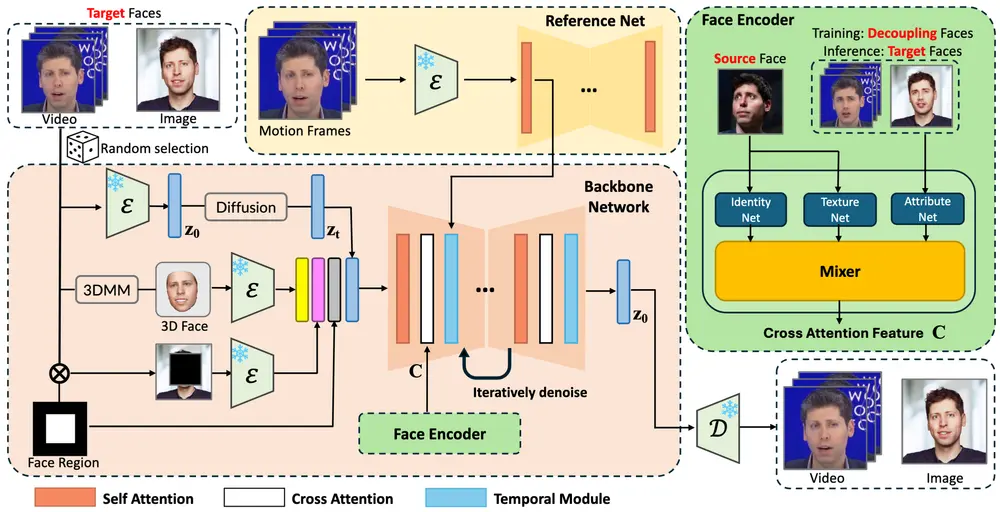
关键技术创新
1、图像-视频混合训练框架:
训练数据选择:在训练过程中,框架随机选择静态图像或视频序列作为训练数据。这种混合训练方式利用了丰富的静态图像数据和时间视频序列,解决了仅视频训练的固有限制。 多模态输入:除了噪声 ( z_t ) 外,框架还集成了三种其他类型的输入来指导生成过程: 人脸区域掩码:用于控制面部图像的生成。 3D 重建人脸:帮助引导姿态和表情,特别是在大幅度姿态变化的情况下。 带掩码的源图像:提供背景信息,确保生成的图像与原始视频背景的一致性。
骨干网络:这些输入通过骨干网络进行处理,执行去噪操作。骨干网络中采用了 交叉注意力 和 时间注意力机制,其中时间注意力模块确保帧之间的时间连续性和一致性。
2、属性-身份解耦三元组(AIDT)数据集:
数据集构建:AIDT 数据集中的每个三元组包含三张人脸图像,其中两张共享相同的姿态,两张共享相同的身份。通过全面的遮挡增强,该数据集还提高了对遮挡的鲁棒性。 解耦能力:AIDT 数据集使 人脸编码器 能够解耦并融合不同的面部组件——身份特征、源人脸的纹理特征以及解耦人脸的属性特征。这增强了泛化能力,特别是在推理过程中源人脸和目标人脸属于不同个体时。
3、VidFaceVAE:
概述:VidFaceVAE 是一个能够同时对图像和视频数据进行编码和解码的模型。某些模块专门为视频输入设计,而图像输入则根据需要绕过这些模块。 功能:VidFaceVAE 在编码和解码过程中有效地处理了静态图像和视频序列的不同特性,确保了生成结果的质量和一致性。
实验结果
大量实验表明,与现有方法相比,VividFace 在以下几个方面表现出色:
身份保留:生成的视频中,目标人脸的身份特征得到了更好的保留。 时间一致性:生成的每一帧在时间上保持一致,避免了闪烁和其他不自然的现象。 视觉质量:生成的视频具有更高的视觉质量,特别是在处理大幅度的姿态变化和遮挡时。 推理效率:所需的推理步骤更少,提升了生成速度和效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











