
北京人工智能研究院推出新型图像生成模型OmniGen,与流行的扩散模型(例如,Stable Diffusion)不同,OmniGen不再需要额外的模块,如ControlNet或IP-Adapter来处理多样的控制条件。你可以把它想象成一个超级万能的画师,它能够根据你给的文字描述或者已有的图片,创作出全新的图像。比如,你给它一个描述:“一个穿着太空服的猫在雪地里”,它就能画出这样一幅画。或者你给它一张图片,然后说“把图中的猫变成一只戴着帽子的猫”,它也能做到。
- GitHub:https://github.com/VectorSpaceLab/OmniGen
- 模型:https://huggingface.co/Shitao/OmniGen-v1
- Demo:https://huggingface.co/spaces/Shitao/OmniGen
- ComfyUI插件:https://github.com/set-soft/ComfyUI_OmniGen_Nodes & https://github.com/set-soft/ComfyUI_OmniGen_Nodes
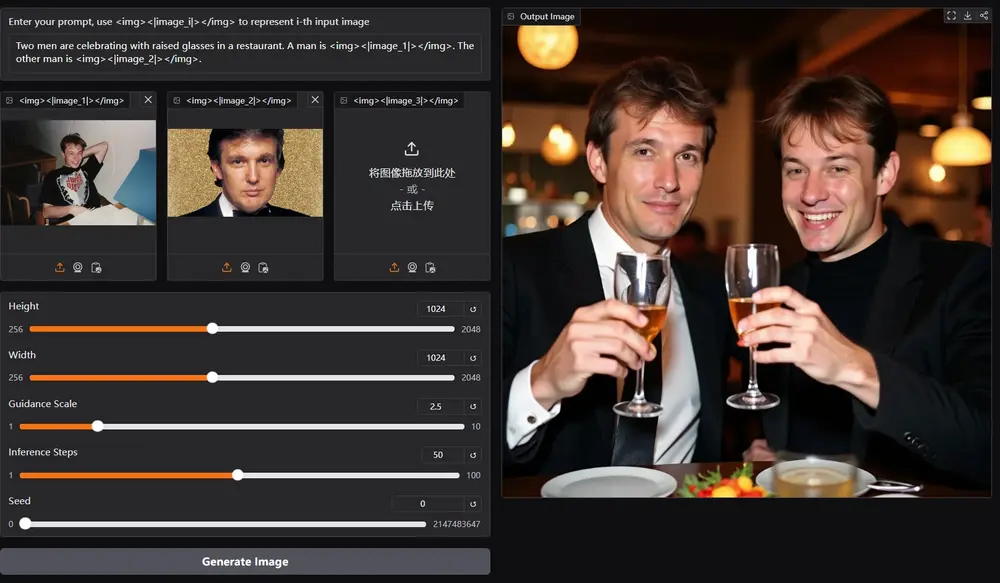
主要功能:
- 文本到图像的生成:根据文字描述生成相应的图像。
- 图像编辑:对现有图像进行修改,比如改变颜色、添加或删除元素。
- 主题驱动生成:根据特定主题或对象生成图像。
- 视觉条件生成:利用视觉元素(如深度图、边缘检测图)来生成图像。
- 经典计算机视觉任务:将一些传统视觉任务转化为图像生成任务,如边缘检测、人体姿态识别。
主要特点:
- 统一性:OmniGen在一个框架内整合了多种图像处理任务,不需要额外的模块。OmniGen不仅展示了文本到图像生成的能力,而且本质上支持其他下游任务,如图像编辑、主题驱动生成和视觉条件生成。此外,OmniGen可以通过将它们转换为图像生成任务来处理经典的计算机视觉任务,例如边缘检测和人体姿态识别。
- 简洁性:模型结构简化,易于使用,减少了预处理步骤。OmniGen的架构高度简化,无需额外的文本编码器。此外,与现有的扩散模型相比,它更加用户友好,使复杂任务可以通过指令完成,无需额外的预处理步骤(例如,人体姿态估计),从而显著简化了图像生成的工作流程。
- 知识迁移:能够在不同任务间迁移知识,处理未见过的领域和任务。通过统一格式的学习,OmniGen有效地在不同任务之间转移知识,管理未见任务和领域,并展现出新的能力。我们还探索了模型的推理能力和链式思维机制的应用潜力。
工作原理: OmniGen使用了一种叫做“扩散模型”的技术。你可以把它想象成一种特殊的化学反应,模型通过逐步去噪的方式,从随机噪声中生成清晰的图像。它首先理解输入的文字或图像条件,然后像艺术家一样逐步绘制出最终的图像。

具体应用场景:
- 艺术创作:艺术家可以使用OmniGen来实现他们的创意构想。
- 游戏和电影制作:设计师可以用它来快速生成概念艺术或场景。
- 虚拟试穿:在时尚领域,用户可以上传自己的照片,OmniGen可以帮助他们预览不同服装的效果。
- 教育和培训:在医学或安全培训中,可以生成逼真的图像来模拟不同的场景。
- 辅助设计:帮助设计师快速迭代和改进产品设计。
总的来说,OmniGen像是一个多功能的数字艺术工具,能够理解和创作视觉内容,为创意产业带来新的可能性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











