特拉维夫大学的研究人员推出新型框架EdgeCape,它用于类别无关的姿态估计(Category-Agnostic Pose Estimation, CAPE)。EdgeCape能够通过单一模型在多样化的对象类别中定位关键点,使用一个或少数几个标注的支持图像。EdgeCape通过其创新的图结构优化和结构偏差机制,为3D姿态估计提供了一个强大而灵活的工具,能够在多种应用中发挥作用。
例如,我们有一张图片,图片中有一个椅子,我们想要定位椅子的关键点,比如椅子的扶手、靠背和椅腿的连接点。EdgeCape能够在没有见过椅子类别的情况下,通过用户提供的支持图像(比如其他椅子的图片)来学习并预测出这些关键点的位置。
主要功能:
- 关键点定位:在不同类别的对象中定位关键点。
- 类别无关性:模型能够泛化到训练时未见过的类别。
- 使用支持图像:利用少数标注图像来辅助姿态估计。
主要特点:
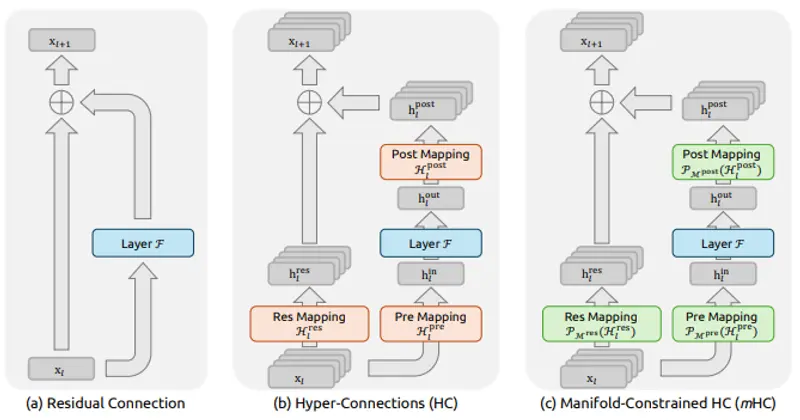
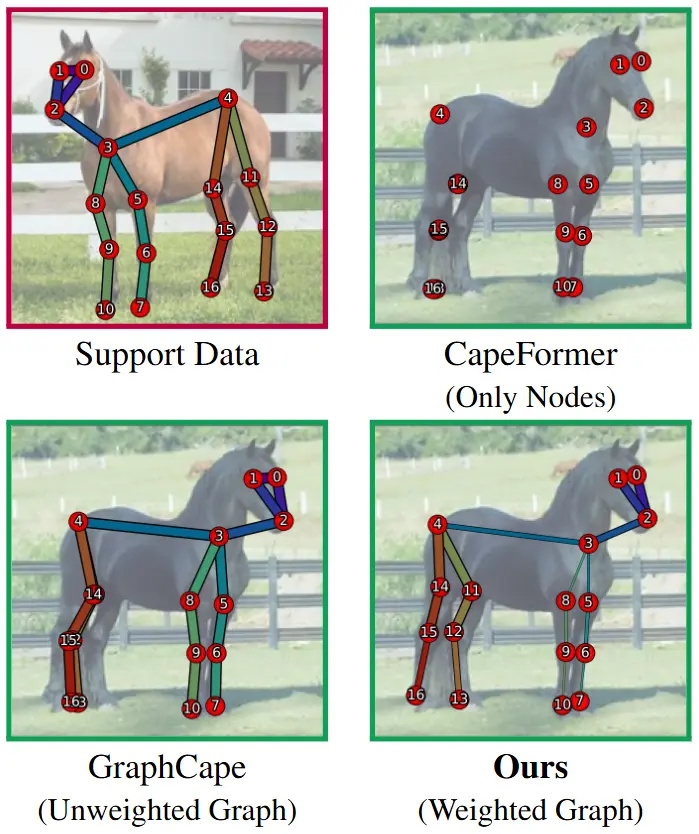
- 预测图的边权重:EdgeCape通过预测图的边权重来优化关键点定位。
- Markovian Structural Bias:引入基于Markov过程的结构偏差,增强模型捕捉全局空间依赖的能力。
- 无需额外训练:利用训练免费反演和修复技术,无需额外的训练即可进行编辑和应用。
工作原理:
EdgeCape框架包括两个主要组件:
- 多视图修正流(Multi-view Rectified Flow, RF)模型:在潜在空间中操作,同时生成多视图图像、深度和相机姿态,这些生成是基于文本提示的条件。
- 高斯绘制解码器(Gaussian Splatting Decoder, GSDecoder):将潜在输出有效地转换成3D高斯绘制(3DGS)表示。
EdgeCape通过预测图的边权重来优化关键点定位,同时利用Markovian Structural Bias来调整Transformer中的自注意力机制,使其能够根据图中节点之间的结构距离调整自注意力权重。
具体应用场景:
- 机器人技术:在机器人抓取和操作任务中,EdgeCape可以帮助机器人识别和定位对象的特定部分。
- 虚拟现实(VR)和增强现实(AR):在虚拟或增强现实环境中,EdgeCape可以用于理解和交互3D对象,提供更加自然和直观的用户体验。
- 动物追踪和车辆定位:在动物追踪和车辆定位中,EdgeCape可以用于精确定位关键点,以便于监控和导航。
- 工业自动化:在工业自动化中,EdgeCape可以用于识别和定位机械部件,以便于自动化装配和质量控制。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











