
来自清华大学、华为诺亚方舟实验室、香港大学的研究人员提出了一种无需训练的组合式文本到图像生成方法CompAgent,该方法利用大语言模型(LLM)智能体进行复杂文本提示的分析与规划,将文本分解为单个对象,逐个解决,最后将生成的图像组合成完整的场景。
CompAgent的核心思想是“分而治之”,即通过分解复杂文本提示,提取单个对象及其属性,然后独立地生成这些对象的图像,最后将它们组合成一张完整的图像。这种方法特别适用于处理包含多个对象、属性和关系的复杂文本描述。

具体来说,CompAgent包含以下几个组成部分:1) LLM智能体,负责对复杂文本进行分解、分析与规划;2) 多概念定制化工具,根据场景布局生成图像,确保属性绑定与关系;3) 布局到图像生成器,根据场景布局生成图像,关注对象关系;4) 局部图像编辑工具,用于替换错误的属性。
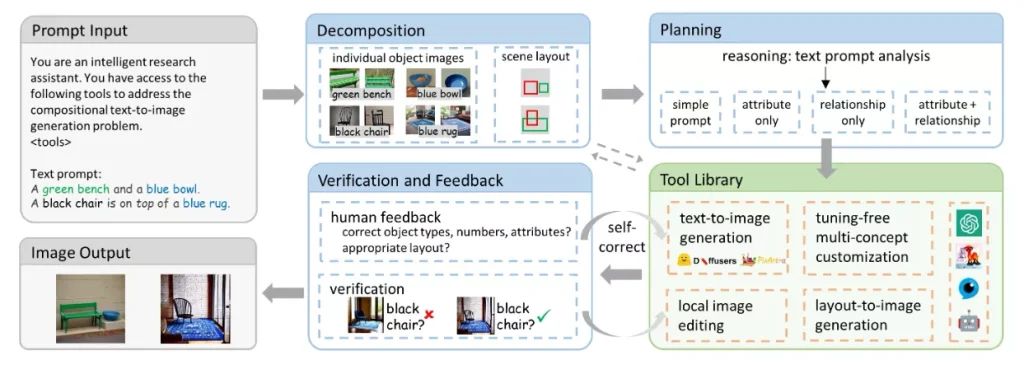
主要特点:
- 分而治之策略:CompAgent将复杂文本分解为单个对象,分别生成图像,然后组合。
- LLM代理:使用大型语言模型作为代理,负责分析文本、规划生成过程和工具选择。
- 无需训练:CompAgent不需要额外的训练,可以直接利用现有的图像生成模型。
- 多概念定制:能够处理包含多个对象的文本提示,生成具有正确对象类型和属性的图像。
- 布局到图像生成:通过布局控制,确保对象间的关系在生成的图像中得到准确表达。
工作原理:
CompAgent的工作流程可以分为以下几个步骤:
- 文本分解:LLM代理首先分析输入的复杂文本,提取出单个对象及其属性。
- 对象生成:使用现有的文本到图像生成模型为每个对象生成图像。
- 布局规划:LLM代理设计场景布局,确定对象在图像中的位置。
- 图像组合:根据布局,将单独生成的对象图像组合成一张完整的图像。
- 验证与反馈:LLM代理或人类用户检查生成的图像,确保对象属性和关系正确无误。如有错误,可以通过局部图像编辑工具进行修正。

该方法在T2I-CompBench基准测试中取得了超过10%的性能提升,展示了在组合式文本到图像生成任务上的卓越表现。此外,CompAgent可以灵活扩展到其他相关任务,如多概念定制化、参考编辑、对象放置等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











