
来自NVIDIA AI、香港中文大学、商汤科技、清华大学、CPII、上海人工智能实验室、Avolution AI的研究人员推出图像到视频生成(I2V)新框架Motion-I2V,它是一个用于将静态图片转换成动态视频的系统。这个系统特别擅长处理包含大量运动和视角变化的场景,并且允许用户精确控制视频中物体的运动轨迹和动画区域。
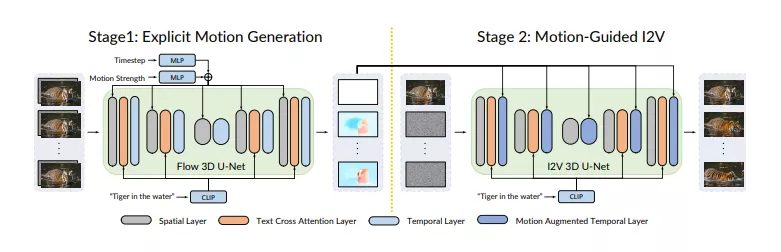
Motion-I2V将I2V分解为两个阶段,并使用显式的运动建模。在第一阶段,提出了基于扩散的运动场预测器,其专注于推导参考图像像素的轨迹。在第二阶段,提出了运动增强的时间注意力,以增强有限的1D时间注意力在视频潜在扩散模型中的作用。
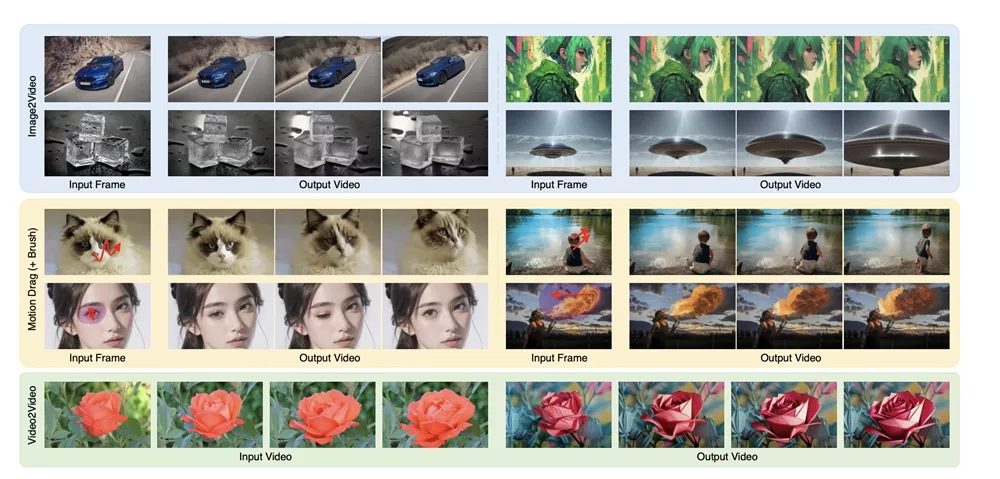
此外,该框架还支持通过训练稀疏轨迹的控制网络,让用户通过简单的轨迹绘制或区域选择来控制生成的视频内容。该框架还可以实现零样本视频到视频的转换。实验结果表明,Motion-I2V在一致性和可控的图像到视频生成方面优于以前的方法。
主要特点:
- 明确的运动建模:Motion-I2V通过预测图片中像素的运动轨迹,使得生成的视频具有高度一致性和逼真的运动效果。
- 用户控制:用户可以通过绘制稀疏轨迹或使用运动刷(motion brush)来精确控制视频中的动画区域,这提供了比仅依赖文本指令更强的控制能力。
- 零样本视频到视频翻译:系统还支持将一个视频转换成另一个风格的视频,用户只需转换第一帧,然后系统会根据源视频的运动轨迹来生成整个视频。
工作原理:
Motion-I2V的工作分为两个阶段:
- 第一阶段:使用一个基于扩散模型的运动场预测器,它接收参考图片和文本指令作为条件,预测所有像素的运动轨迹。
- 第二阶段:提出一种运动增强的时间注意力机制,它根据第一阶段预测的运动轨迹,通过自适应(通过交叉注意力)将参考图片的特征映射到合成帧中,从而生成连贯的动画。
应用场景:
Motion-I2V可以应用于多个领域,包括电影制作、增强现实、自动广告生成以及社交媒体内容创作。例如,它可以将静态的艺术作品或照片转换成动态视频,或者将一个视频的风格转换为另一个风格,同时保持第一帧的静态图像。此外,它还可以用于教育和娱乐,帮助用户以更直观的方式展示和理解动态过程。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











