
阿里云宣布通义千问视觉理解模型 Qwen-VL 再次升级,继 Plus 版本之后推出 Max 版本,升级版模型拥有更强的视觉推理能力和中文理解能力,能够根据图片识人、答题、创作、写代码,并在多个权威测评中获得佳绩,比肩 OpenAI 的 GPT-4V 和谷歌的 Gemini Ultra。
- Qwen-VL-Plus:通义千问大规模视觉语言模型增强版。大幅提升细节识别能力和文字识别能力,支持超百万像素分辨率和任意长宽比规格的图像。在广泛的视觉任务上提供卓越的性能。
- Qwen-VL-Max:通义千问超大规模视觉语言模型。相比增强版,再次提升视觉推理能力和指令遵循能力,提供更高的视觉感知和认知水平。在更多复杂任务上提供最佳的性能。
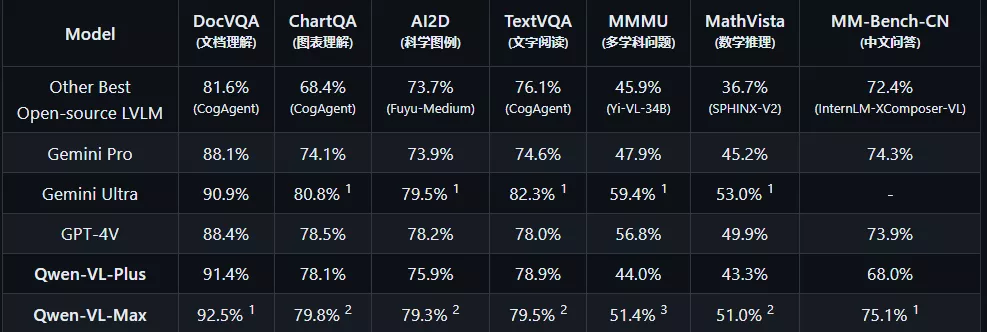
这两个版本的主要技术升级在于:
- 大幅提升图像相关的推理能力;
- 大幅提升对图中细节和文字的识别、提取和分析能力;
- 支持百万像素以上的高清分辨率图,支持各种长宽比的图像;
如何使用?
目前 Qwen-VL-Plus 和 Qwen-VL-Max 限时免费,用户可以在通义千问官网、通义千问 APP 直接体验 Max 版本模型的能力,也可以通过阿里云灵积平台(DashScope)调用模型 API。
当前,用户可以通过Huggingface Spaces、通义千问官方网站以及Dashscope APIs来使用Qwen-VL-Plus和Qwen-VL-Max模型。
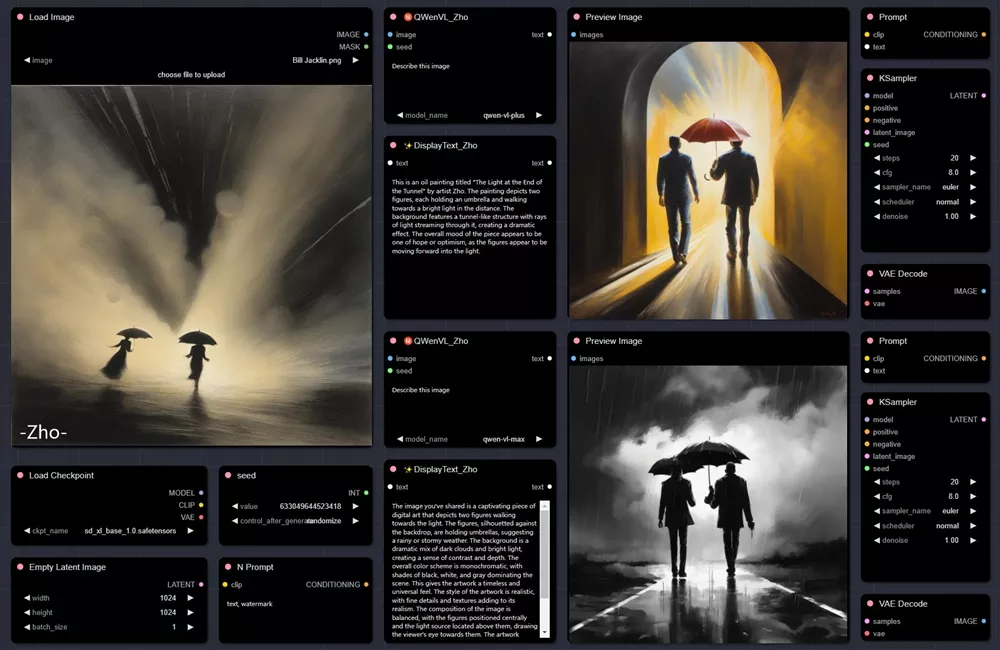
QWen-VL in ComfyUI
目前已经有开发者将Qwen-VL引入ComfyUI,可用于后续图生图。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











