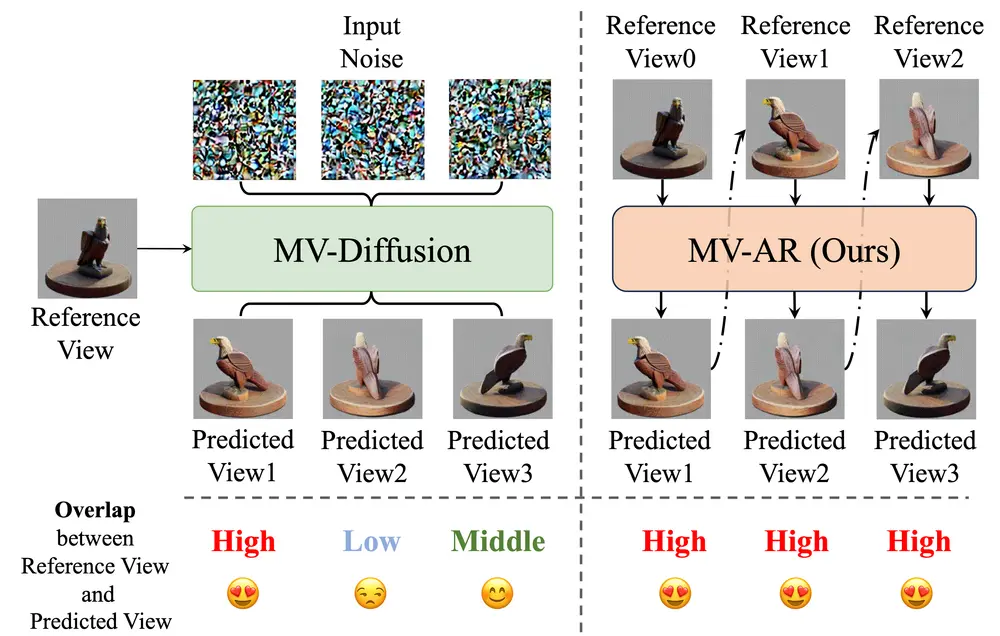
中国科学技术大学的研究人员推出视频编辑方法STABLEV2V,旨在解决视频编辑中形状一致性问题。STABLEV2V通过一系列顺序过程来编辑视频:首先编辑第一帧视频,然后建立交付动作与用户提示之间的对齐,并最终基于这种对齐将编辑内容传播到所有其他帧。此外,研究者还创建了一个测试基准DAVIS-Edit,用于全面评估视频编辑,考虑了各种类型的提示和难度。
- 项目主页:https://alonzoleeeooo.github.io/StableV2V
- GitHub:https://github.com/AlonzoLeeeooo/StableV2V
- 模型:https://huggingface.co/AlonzoLeeeooo/StableV2V
- 数据集:https://huggingface.co/datasets/AlonzoLeeeooo/DAVIS-Edit
例如,你有一个视频,视频中有一只乌龟在河里游泳,你想将乌龟变成乐高风格的乌龟。使用STABLEV2V,你可以通过提供文本描述“Make it lego”和参考图像(例如,一个乐高风格的物体图片)来指导编辑过程。STABLEV2V将分析这些输入,并在保持视频原有动作模式的同时,将乌龟转换成乐高风格,并在整个视频中保持这种风格。

主要功能和特点
主要功能:
- 形状一致性编辑: 确保编辑后的视频内容在形状上与用户提示保持一致。
- 顺序编辑流程: 先编辑第一帧,然后对齐动作,最后将编辑内容传播到所有帧。
- 测试基准: 提供DAVIS-Edit基准,用于评估视频编辑方法。
主要特点:
- 无需额外训练: STABLEV2V不需要额外训练即可改善视频编辑任务。
- 视觉质量和一致性: 实验结果显示,STABLEV2V在视觉质量和一致性方面优于现有方法。
- 推理效率: STABLEV2V在保持高效率的同时,实现了高质量的视频编辑。
工作原理
STABLEV2V的工作原理包括以下几个步骤:
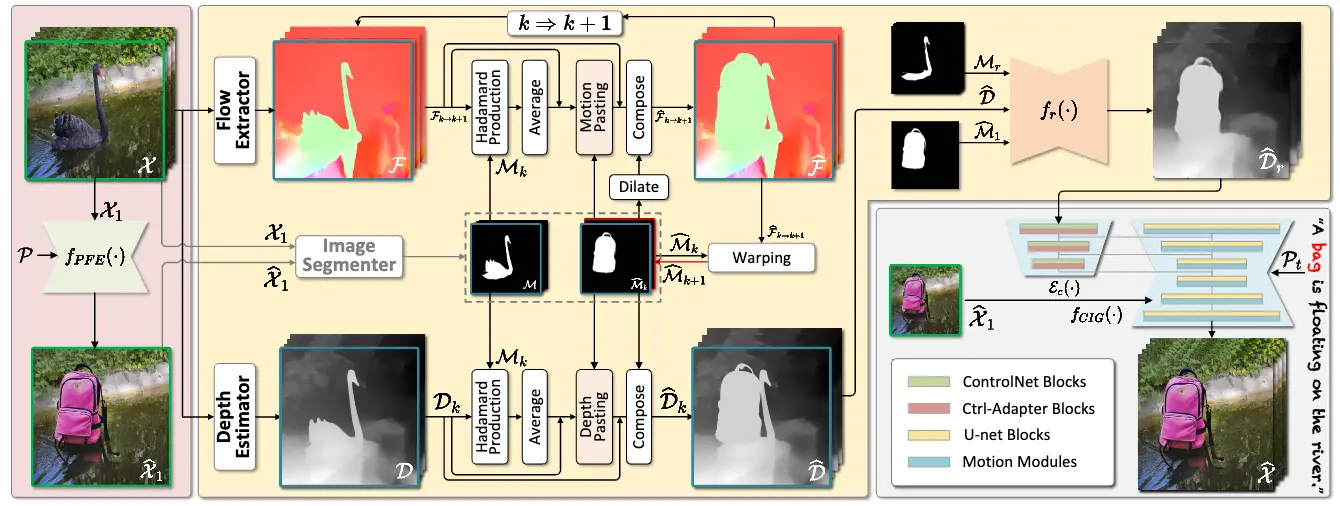
- 第一帧编辑(PFE): 将外部提示(如文本、图像)转换为第一帧视频的编辑内容。
- 迭代形状对齐(ISA): 从原始视频帧中提取深度图、光流和分割掩码,模拟编辑视频的深度图,并使用形状引导的深度细化网络来校准深度图,确保精确性。
- 条件图像到视频生成器(CIG): 使用深度图作为中间载体,传递精确的动作信息,并指导图像到视频的生成过程,最终生成编辑后的视频。
具体应用场景
- 文本引导的视频编辑: 根据文本提示编辑视频内容,如将视频中的对象替换为用户指定的风格或对象。
- 图像引导的视频编辑: 使用参考图像来指导视频内容的编辑,如将视频中的物体替换为图像中的风格或物体。
- 视频风格转换: 改变视频的整体风格,如将视频场景转换为梵高风格。
- 视频修复和擦除: 在视频中移除不需要的对象或场景,并自然地填补空白区域。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











