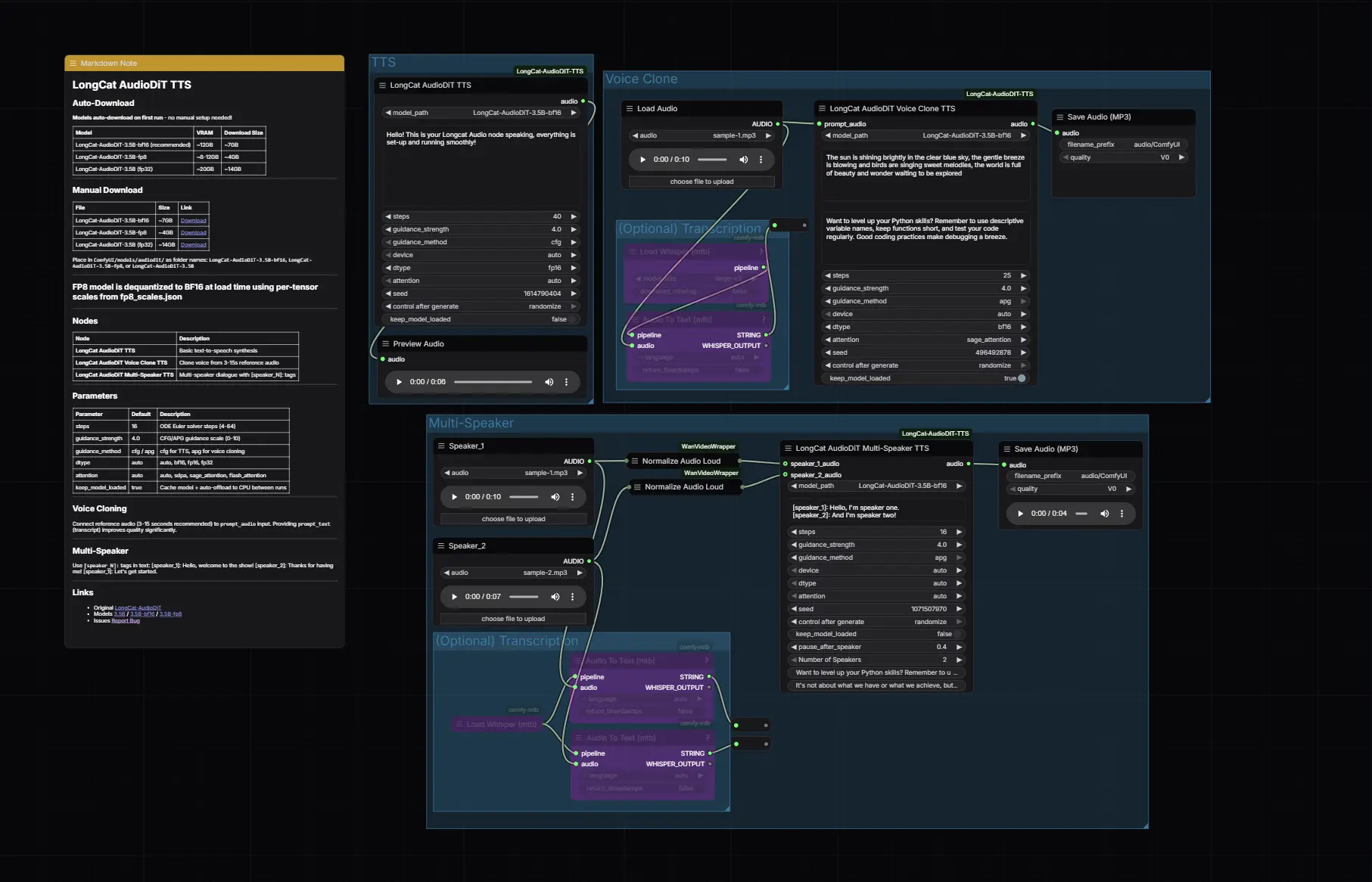
尽管基于图像的虚拟试穿技术已取得显著进展,但在生成高保真度和适应性强的拟合图像上仍面临诸多挑战。尤其在纹理感知维护和尺寸感知拟合等关键领域,现有方法往往难以达到理想效果,这限制了技术的整体实用性。为应对这些挑战,腾讯与复旦大学的研究团队共同开发了一项创新技术——FitDiT。

这项技术专为优化DiT(Diffusion in Time)模型的虚拟试穿性能而设计,特别强调提升高分辨率特征的处理能力,通过增加参数分配和加强注意力机制来改善图像质量。例如,你在网上购物时想要试穿一件衣服,但不想实际穿上它。使用FitDiT技术,你只需上传一张个人照片和想要试穿的衣服图片,系统就能生成一张你穿着该衣服的逼真效果图,包括衣服的纹理、图案和适配你的身材大小。
- GitHub:https://github.com/BoyuanJiang/FitDiT
- 论文:https://arxiv.org/abs/2411.10499
- 模型:https://huggingface.co/BoyuanJiang/FitDiT
- Demo:https://huggingface.co/spaces/BoyuanJiang/FitDiT
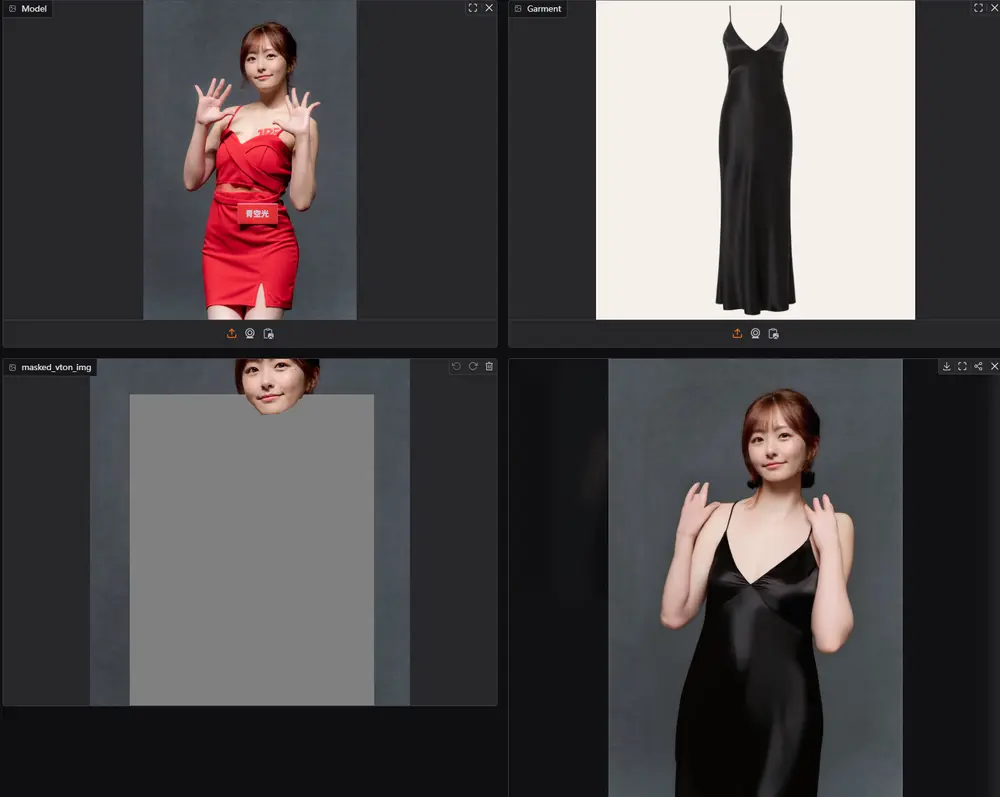
FitDiT的核心改进点
纹理感知维护的增强
- 服装纹理提取器:FitDiT引入了一种新的服装纹理提取器,该提取器利用服装先验知识对服装特征进行微调,以更准确地捕捉复杂的纹理细节,如条纹、图案和文字。
- 频率域学习:通过引入定制的频率距离损失,FitDiT能够在频率域中学习,从而强化对高频服装细节的表达,进一步提高了纹理的真实感和细节度。
尺寸感知拟合的优化
- 扩张-放松的掩模策略:为解决跨类别试穿时服装尺寸适配的问题,FitDiT采用了一种独特的扩张-放松掩模策略。这种方法可以根据不同类型的服装自动调整其长度,避免了服装在图像中占据不适当位置的情况,确保了试穿效果的自然性和准确性。
主要功能和特点
主要功能:
- 高保真虚拟试穿: 生成逼真的试穿效果图,保留衣服的复杂纹理和细节。
- 尺寸感知适配: 确保衣服在不同体型的人身上试穿时尺寸合适,避免衣服覆盖整个模板区域的问题。
主要特点:
- 纹理感知保持: 通过衣物纹理提取器和频率域学习,增强衣物细节,如条纹、图案和文字。
- 结构瘦身: 优化DiT结构,去除不必要的文本编码器,节省参数并提高训练和推理速度。
- 衣物条件调制: 使用OpenCLIP图像编码器对给定衣物进行编码,以衣物感知的方式调制DiT块中的特征。
- 衣物特征注入: 将衣物的详细特征从GarmentDiT注入到DenoisingDiT中,通过混合注意力机制实现。
工作原理
FitDiT的工作原理基于以下几个步骤:
- 衣物特征提取: 使用GarmentDiT从输入的衣物图像中提取详细特征。
- 混合注意力注入: 将提取的衣物特征通过混合注意力机制注入到DenoisingDiT中。
- 结构瘦身和调制: 定制DiT结构,去除文本编码器,使用衣物图像嵌入来调制特征。
- 扩张放松掩模策略: 使用随机调整的粗略矩形掩模,避免训练过程中衣物形状信息的泄露。
- 频率域学习: 通过最小化生成图像和真实图像在频率域的差异,增强衣物细节的重建保真度。
性能表现
FitDiT在多项测试中展现了卓越的能力,不仅在定性和定量评估中均超越了现有技术,而且在生成逼真、复杂细节的合身服装图像方面表现出色。此外,经过优化后的FitDiT模型对于单张分辨率为1024x768的图像,其推理时间仅为4.57秒,这在同类技术中处于领先地位,证明了其高效性和实用性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...