
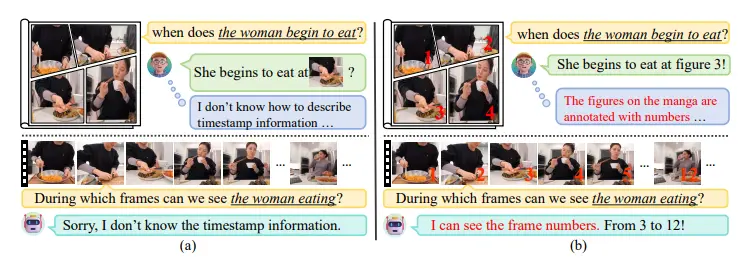
东南大学、马克斯普朗克信息学研究所、腾讯微信和加州大学伯克利分校的研究人员推出了一个名为Number-Prompt(NumPro)的方法,它旨在增强视频大语言模型(Vid-LLMs)在视频时间定位(Video Temporal Grounding,VTG)任务中的表现。VTG任务要求模型能够精确识别视频中特定事件的时间戳,例如确定某个动作发生的具体帧数或秒数。NumPro通过在每个视频帧上添加唯一的数字标识符(类似于漫画面板上的编号),使Vid-LLMs能够直观地“阅读”事件时间线,将视觉内容与对应的时间信息准确关联。
例如,你正在观看一个烹饪视频,想要找到厨师加入香料的确切时刻。在没有时间标记的情况下,即使是先进的Vid-LLMs也可能难以精确定位这一动作发生的具体时间。通过使用NumPro,每个视频帧都会显示一个数字,比如“3”到“12”,表示这一动作发生在第3帧到第12帧之间。这样,模型就可以直接“读取”这些数字,将视觉信息与时间信息关联起来,从而准确回答关于时间的问题。
主要功能:
- 时间定位增强: 通过在视频帧上添加数字标识符,增强Vid-LLMs在视频时间定位任务中的表现。
- 无需额外训练: NumPro可以在不增加额外训练成本的情况下直接应用于现有的Vid-LLMs。
- 提高性能: 在多个标准VTG基准测试中,NumPro显著提高了Vid-LLMs的性能。
主要特点:
- 直观性: 将视频时间定位任务转化为类似翻阅编号漫画面板的直观过程。
- 简单性: 通过简单地在视频帧上添加数字标识符,实现了对Vid-LLMs的时间定位能力的增强。
- 可转移性: NumPro不需要修改模型的词汇表或引入额外的标记,保持了模型的强转移性。
工作原理
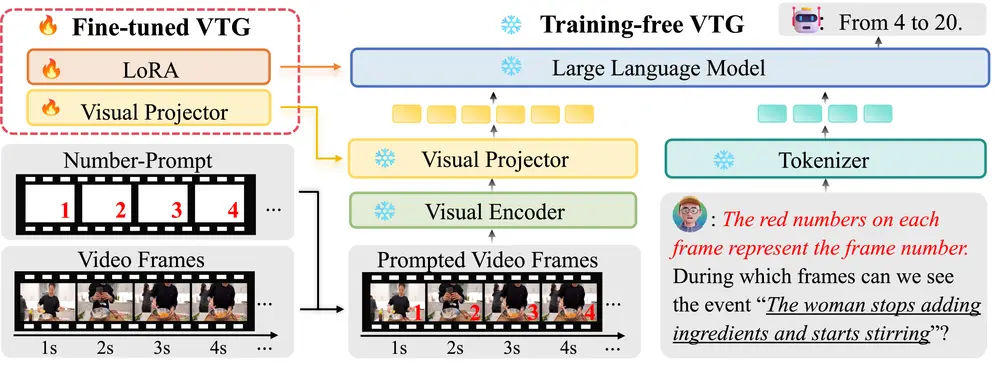
NumPro的工作原理包括以下几个步骤:
- 帧编号: 在每个视频帧上添加一个唯一的数字标识符,表示其在视频序列中的位置。
- 视觉-语言对齐: 利用Vid-LLMs内置的光学字符识别(OCR)能力,使模型能够“读取”这些数字,并将其与视觉内容关联起来。
- 查询处理: 当给定一个针对事件的语言查询时,Vid-LLMs检索与查询相关的视频帧的视觉特征,并将其与覆盖的帧数字关联。
- 文本输出: 将数字标识符直接转换为文本输出,从而实现对事件时间边界的精确描述。
具体应用场景
- 视频问答系统: 在视频问答系统中,用户可以询问视频中特定事件的时间位置,系统能够准确回答。
- 视频内容分析: 在视频内容分析中,NumPro可以帮助模型更好地理解视频中事件的时间发展。
- 视频编辑和摘要: 在视频编辑和摘要生成中,NumPro可以帮助识别和定位关键事件,从而生成更准确的视频摘要。
- 视频搜索和检索: 在视频搜索和检索中,NumPro可以提高视频检索系统对时间敏感查询的响应能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











