
来自滑铁卢大学、Vector Institute、Harmony.AI、多模式艺术投影研究社区的研究人员提出了一种基于扩散的图像到视频生成新方法CONSISTI2V,它旨在通过增强视觉一致性来改善视频生成的质量。简单来说,就是让计算机根据一张图片和一些文字描述,生成一段连贯、自然的视频。
具体来说,该方法通过在空间和时间层中进行第一帧的条件化,实现了生成的视频在视觉质量上的提升。同时,该方法还引入了一种在推理阶段引导噪声初始化的策略,即FrameInit,该策略利用第一帧的低频成分来稳定视频生成过程。
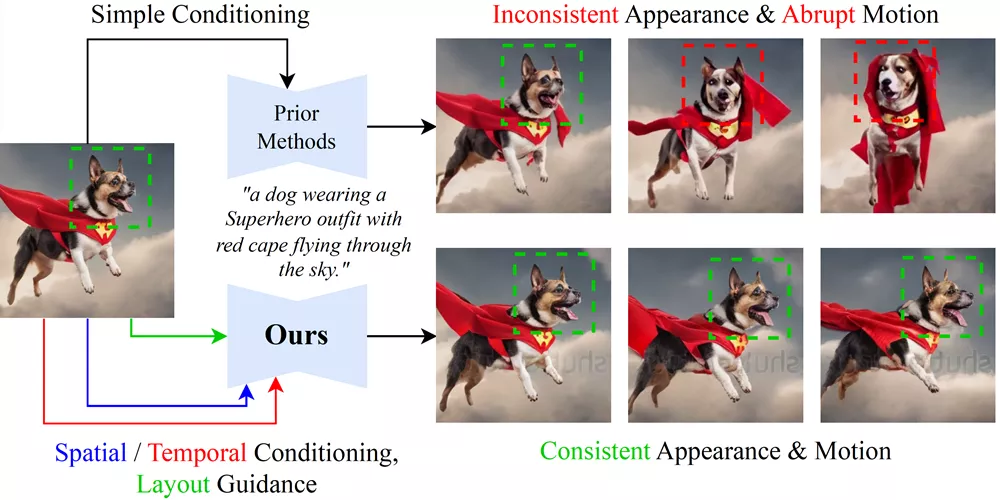
此外,该团队还构建了一个全面评估图像到视频生成模型性能的基准测试集I2V-Bench。大量的实验结果表明,CONSISTI2V在各种评估指标上均优于现有的图像到视频生成方法,并展示了其在自动回归长视频生成和相机运动控制等应用场景中的潜力。
主要功能:
- 生成与输入图片风格、内容和背景一致的视频。
- 保持视频中主体、背景和风格的一致性。
- 提供流畅且逻辑性强的视频叙事。
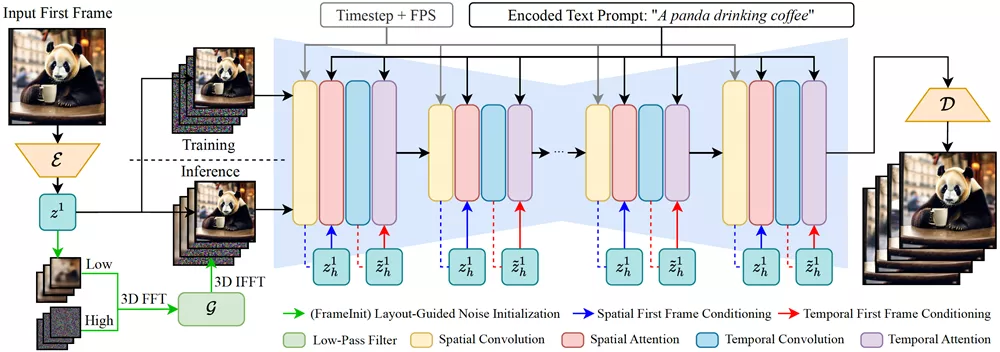
主要特点:
- 空间和时间注意力机制:通过在模型的空间层应用跨帧注意力机制,确保视频中的每个帧都能精细地反映第一帧的特征。
- 低频噪声初始化:在推理过程中,利用第一帧图像的低频部分作为布局指导,消除训练和推理过程中噪声的不一致性。
- I2V-Bench评估基准:提出了一个全面的评估基准,用于评价I2V生成模型的性能。

工作原理:
- 模型架构:基于文本到图像(T2I)的潜在扩散模型(LDMs),使用U-Net结构进行视频生成。
- 第一帧条件注入:将输入的第一帧图像编码为潜在表示,并将其作为条件信号注入到模型中。
- 细粒度空间特征条件:在空间自注意力层中,通过包含第一帧的特征,实现对视频中每个帧的精细特征条件。
- 基于窗口的时间特征条件:在时间自注意力层中,通过包含第一帧的局部特征窗口,增强时间平滑性和连贯性。
- 推理时布局引导噪声初始化:在推理过程中,结合第一帧的低频成分和初始噪声,引导视频生成过程,提高视频质量。
CONSISTI2V通过这些创新的方法,能够在保持视觉一致性的同时,生成更加自然和吸引人的视频内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











