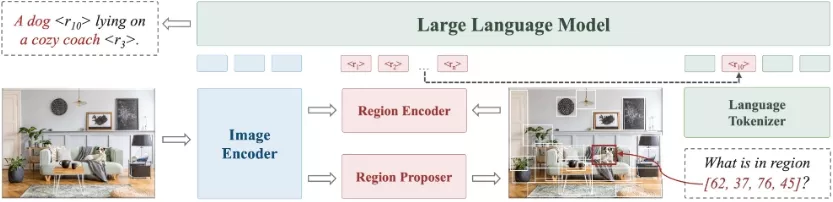
来自香港大学和字节跳动的研究人员推出多模态大语言模型Groma,它具备精细化和定位化的视觉感知能力。Groma不仅能够理解整个图像的内容,还能处理区域级别的任务,比如区域字幕(region captioning)和视觉定位(visual grounding)。这些能力基于一种局部视觉标记化(localized visual tokenization)机制,该机制将图像输入分解为感兴趣区域(regions of interest, ROIs),然后将这些区域编码成区域标记(region tokens)。
通过将区域标记融入用户指令和模型响应中,Groma能够无缝地理解用户指定的区域输入,并将其文本输出精准地与图像相关联。此外,为了进一步提升Groma基于视觉的交互能力,开发人员利用先进的GPT-4V和视觉提示技术,精心打造了一个基于视觉的指令数据集。与那些依赖语言模型或外部模块进行定位的多模态大型语言模型相比,Groma在标准的指代和定位基准测试中展现出了卓越的性能,这凸显了将定位能力嵌入到图像分词机制中的优势。

主要功能:
- 区域字幕:Groma能够为图像的特定区域生成描述性的字幕。
- 视觉定位:Groma能够识别用户指定的图像区域,并在生成文本时与这些视觉内容关联。
主要特点:
- 局部视觉标记化:Groma使用局部视觉标记化机制来理解和编码图像的不同区域。
- 无需外部模块:与依赖外部定位模块的方法不同,Groma将定位任务嵌入到图像标记化过程中,这样做既节省了计算资源,又保持了定位的准确性。
- 统一的输入和输出格式:Groma使用统一的格式来处理引用(referring)和定位(grounding)任务,简化了模型的复杂性。
工作原理:
- 图像编码器:Groma使用预训练的DINOv2模型作为图像编码器,将图像转换为图像标记。
- 区域提议器:Groma创新性地引入了一个区域提议器,用于发现图像中的感兴趣区域。
- 区域编码器:区域编码器将区域提议器生成的区域提议(即边界框)转换为区域标记。
- 大型语言模型:Groma采用预训练的Vicuna模型作为语言模型,用于处理多模态输入和输出。
具体应用场景:
假设你正在使用一个图像检索系统,你想要系统描述图像中特定区域的内容。例如,你上传了一张包含多个人和物体的照片,并询问系统:“照片中的第三个人物在做什么?”Groma能够识别出你指的是哪个人物,并且生成关于这个人物活动的描述。
在实验中,Groma在多个标准参照和定位基准测试中展示了其优越性,与依赖语言模型或外部模块进行定位的MLLMs相比,Groma在这些任务中表现更好。此外,Groma还在对话式视觉问答(VQA)基准测试中保持了强大的图像级理解和推理能力,证明了其在多种区域级任务中的有效性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...