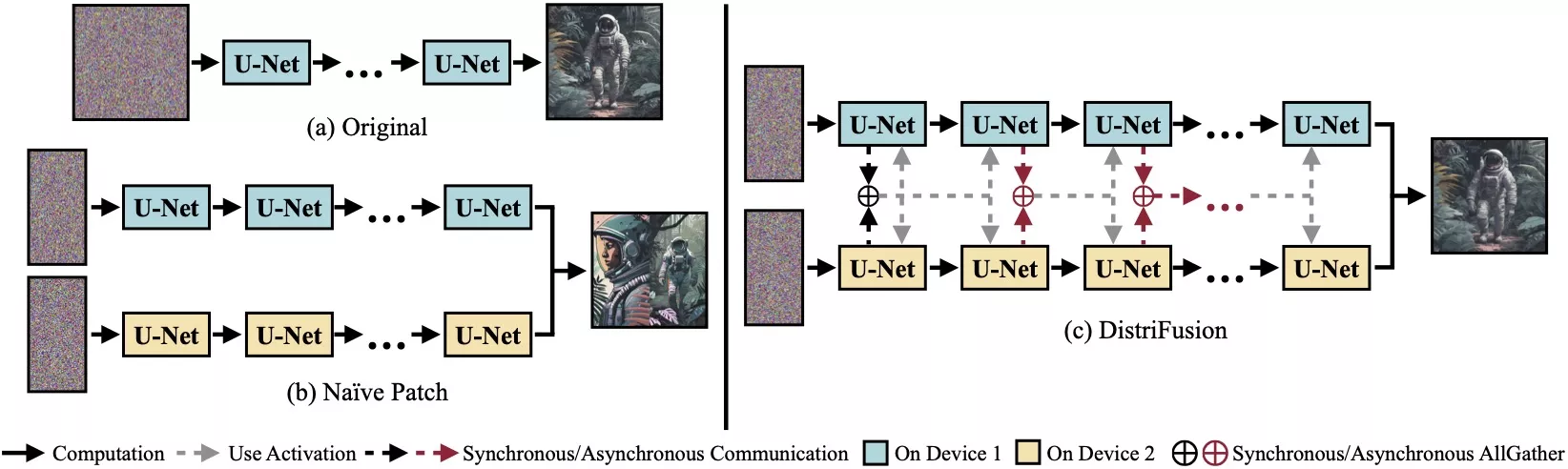
来自麻省理工学院、普林斯顿大学、Lepton AI 和 英伟达的研究人员推出DistriFusion,这是一种用于加速高分辨率扩散模型(diffusion models)的并行推理算法。
扩散模型在生成高质量图像方面取得了显著成功,但生成高分辨率图像时的计算成本非常高,导致交互应用的延迟问题。DistriFusion通过在多个GPU之间进行并行处理来解决这个问题,同时不牺牲图像质量。

主要功能:
- 加速高分辨率图像的生成:DistriFusion能够显著减少生成高分辨率图像所需的时间,使得实时应用成为可能。
- 保持图像质量:即使在加速过程中,DistriFusion也能够保持与原始模型相同的图像质量。
主要特点:
- 无需训练:DistriFusion不需要对模型进行额外训练,可以直接应用于现有的预训练扩散模型。
- 并行处理:通过将图像分割成多个小块(patches),并分配给不同的GPU进行处理,实现并行计算。
- 异步通信:DistriFusion利用异步通信机制,将通信开销隐藏在计算过程中,提高了效率。
工作原理:
- 图像分割:将输入图像分割成多个小块,每个小块分配给一个GPU。
- 并行推理:每个GPU独立处理其分配的图像块,通过异步通信共享必要的信息。
- 激活重用:利用扩散过程中相邻步骤输入的高相似性,重用前一步骤的激活信息,以提供当前步骤的上下文信息。
- 稀疏计算:仅在图像块的新区域执行计算,减少了每个设备的计算负担。
核心优势:
DistriFusion方法的核心优势在于其能够保持预训练扩散模型的参数不变,同时通过并行处理来加速图像生成过程。这意味着在处理不同类型和风格的图像时,通常不需要调整模型的参数。用户可以直接使用DistriFusion来加速现有的扩散模型,如Stable Diffusion XL,而无需对模型结构或参数进行修改。

然而,为了获得最佳的图像质量和生成速度,可能需要对并行处理的配置进行一些调整,例如:
- 设备分配:根据可用的GPU数量和性能,可以调整分配给每个图像块的GPU数量。
- 通信策略:虽然DistriFusion已经通过异步通信来优化通信开销,但在某些情况下,可能需要调整通信的策略,以确保数据传输不会成为瓶颈。
- 计算资源分配:在多GPU环境中,可能需要调整每个GPU的计算资源分配,以确保所有设备都能高效地工作。
- 采样步骤:对于不同的图像分辨率和复杂度,可能需要调整生成过程中的采样步骤数量。DistriFusion在实验中展示了在不同分辨率下的性能,这表明它能够适应不同的图像生成需求。
- 预热步骤:在某些情况下,为了提高图像质量,尤其是在使用较少采样步骤的情况下,可能需要在并行处理之前执行一些预热步骤。
DistriFusion的设计目标是提供一个通用的加速框架,它能够适应多种图像生成任务,而不需要对模型本身进行调整。然而,为了优化特定应用的性能,可能需要对并行处理的配置进行微调。
简而言之,DistriFusion是一个创新的算法,它通过在多个GPU上并行处理图像,显著提高了高分辨率图像生成的速度,同时保持了图像质量,为各种需要快速高质量图像生成的应用场景提供了可能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











