
Meta Motivo 是一个创新的行为基础模型,旨在通过一种新的无监督强化学习(RL)算法——前向-后向表示与条件策略正则化(FB-CPR),来控制复杂虚拟人形代理的运动。该模型能够在测试时通过提示解决未见过的任务,如运动跟踪、姿势到达和奖励优化,而无需任何额外的学习或微调。Meta Motivo的目标是构建能够推广到更复杂任务的行为基础模型,并可能适用于不同类型的代理。

关键要点
1、新算法:FB-CPR
前向-后向表示:该算法结合了无监督前向-后向表示学习和模仿学习损失,用于正则化策略以覆盖未标记轨迹数据集中的状态。 条件策略正则化:通过直接访问环境进行在线训练,FB-CPR学习将状态、运动和奖励的嵌入对齐到相同的潜在空间。这使得模型能够以有用的行为为基础,同时在广泛的任务中进行零样本推理。
2、行为基础模型
Meta Motivo 是一个行为基础模型,可以控制高维虚拟人形代理解决广泛的任务。它通过无监督的方式学习复杂的运动技能,并能够在未见过的任务中表现出色。 两个主要组件: 嵌入网络:接收代理状态作为输入,并返回其嵌入。 策略网络:接收状态作为输入,并返回要采取的动作。该策略网络参数化了嵌入,使得模型能够在不同的任务中进行零样本推理。
3、任务范围
运动跟踪:模型可以通过提示跟踪复杂的运动序列,如侧手翻。 姿势到达:模型可以调整代理的姿态以达到特定的姿势,如阿拉贝斯克姿势。 奖励优化:模型可以根据给定的奖励函数优化代理的行为,如跑步速度或稳定性。
4、预训练过程
模拟环境:Meta Motivo使用基于 SMPL 的人形代理在 Mujoco 模拟器上进行训练。 数据集:训练过程中使用了 AMASS 运动捕捉数据集的一个子集,以及 3000万次在线交互样本。 性能改进:尽管模型没有明确训练以优化特定任务,但在预训练过程中,我们观察到了运动跟踪、姿势到达和奖励优化任务中性能的显著提升,且行为变得更加类似人类。
5、评估结果
新的人形基准:为了评估模型的性能,Meta开发了一个新的人形基准,涵盖运动跟踪、姿势到达和奖励优化任务。 定量评估:Meta Motivo在每个任务重新训练的顶级方法的性能中达到了 61% 到 88%,并优于所有其他算法,除了在跟踪任务中略逊于 Goal-TD3。 定性评估:通过人类评估,Meta Motivo在基于奖励和基于目标任务之间的性能差距得到了进一步分析。结果显示,Meta Motivo在性能和定性行为之间取得了更好的平衡,生成的行为更加自然,而纯粹为性能优化的策略(如TD3)则显得不够自然。
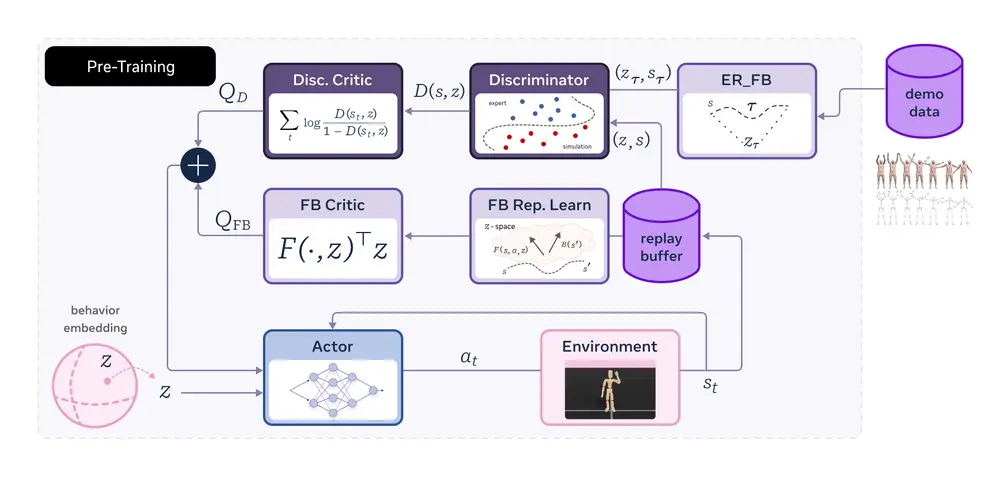
算法详解:FB-CPR
前向-后向表示学习 FB-CPR通过无监督的方式学习状态、动作和奖励的嵌入,并将它们对齐到同一个潜在空间中。前向表示从初始状态开始,逐步预测未来的状态和奖励;后向表示从最终状态开始,逐步预测过去的动作和状态。通过这种方式,模型可以学习到一个鲁棒的状态表示,能够捕捉到运动的动态特性。
条件策略正则化 条件策略正则化通过引入模仿学习损失,确保策略能够覆盖未标记轨迹数据集中的状态。具体来说,FB-CPR通过最小化策略输出的动作与真实轨迹中动作之间的差异,来正则化策略。这使得模型能够在未见过的任务中表现出更广泛的行为多样性。
零样本推理 由于FB-CPR将状态、动作和奖励嵌入到同一个潜在空间中,模型可以在测试时通过提示(如目标姿态或奖励函数)进行零样本推理。这意味着模型可以在没有额外训练的情况下,快速适应新的任务要求。
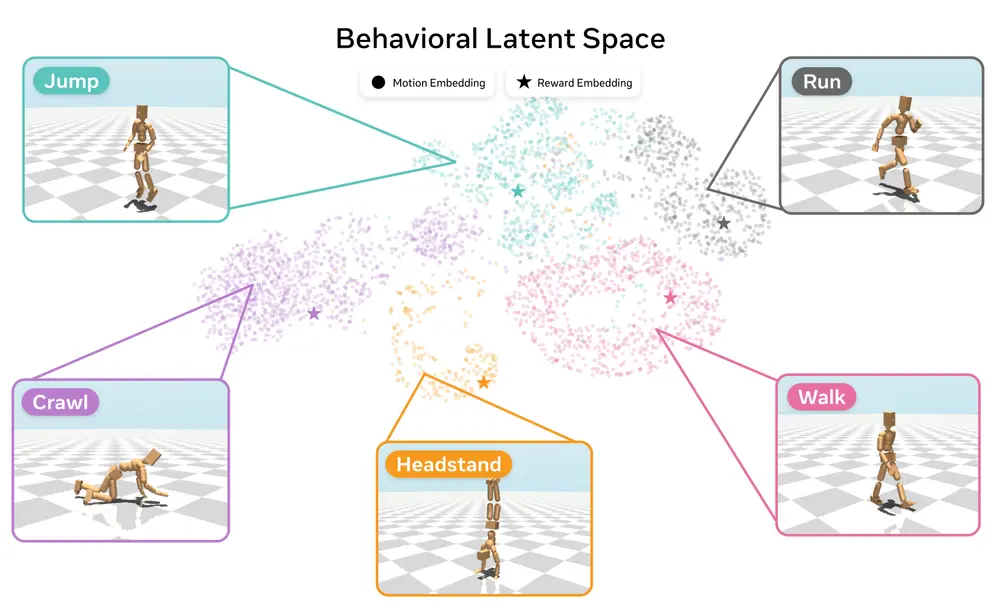
行为潜在空间的理解
1、潜在空间结构
FB-CPR的一个关键特性是它使用相同的表示将状态、奖励和运动嵌入到相同的空间中。通过研究学习到的行为潜在空间的结构,我们可以更好地理解模型如何组织和生成不同的行为。 例如,潜在空间中的不同区域可能对应于不同的运动模式或行为类型。通过对这些区域的分析,研究人员可以进一步探索如何设计更有效的提示,以引导模型生成特定的行为。
2、可视化与解释
为了更好地理解潜在空间的结构,Meta团队进行了可视化分析。结果显示,潜在空间中的不同维度确实捕捉到了运动的不同特征,如速度、方向和姿态。这种可视化的工具可以帮助研究人员调试模型,并为未来的研究提供有价值的见解。
代码与基准发布
Meta Motivo的发布不仅包括预训练模型,还提供了新的人形基准和训练代码。这些资源的公开发布旨在鼓励社区进一步发展研究,推动行为基础模型的发展。研究人员可以使用这些工具来评估和改进自己的模型,或者探索新的应用领域。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











