中国科学技术大学和科大讯飞研究院的研究人员推出新框架DAWN,它能够根据单一的肖像图像和语音音频剪辑生成生动、逼真的头部动画视频。这项技术的核心在于使用非自回归(NAR)扩散模型来一次性生成动态长度的视频序列,这意味着它可以快速生成任意长度的视频,而不需要逐帧或逐段生成。
例如,你想在视频会议中使用自己的头像,但希望这个头像能够根据你说的话做出相应的唇部动作和表情。DAWN就可以根据你提供的一张静态照片和你的声音,快速生成一个动态的、逼真的头像视频,让你在虚拟会议中的形象更加生动。

主要功能和特点:
- 非自回归生成:DAWN采用了非自回归策略,这使得它能够快速生成视频,同时避免了自回归模型中常见的错误累积和生成速度慢的问题。
- 动态帧生成:能够根据语音和肖像图像生成任意长度的视频,这在以往的技术中是很难实现的。
- 精确的唇部动作:视频中的唇部动作能够精确匹配伴随的语音,这对于生成逼真的头部动画视频至关重要。
- 自然的姿态和眨眼动作:除了唇部动作,DAWN还能生成自然的头部姿态和眨眼动作,使得生成的视频更加自然和逼真。
- 高质量的视频生成:DAWN在生成视频时能够保持高质量的视觉效果,同时具有强大的外推能力,确保了长时间视频的稳定生产。
工作原理:
DAWN框架主要包括三个部分:
- 潜在流生成器(LFG):用于从源图像和驱动图像之间估计潜在空间中的运动表示。
- 音频到视频流扩散模型(A2V-FDM):用于从给定的音频和肖像中生成运动表示序列,这些序列随后被用来重建视频。
- 姿态和眨眼生成网络(PBNet):用于从音频中生成头部姿态和眨眼动作,这些动作随后被用来控制A2V-FDM中的内容。
此外,DAWN还采用了两阶段课程学习(TCL)策略,以指导模型在生成准确的唇部动作和精确的姿态/眨眼动作控制方面取得更好的收敛性和外推能力。
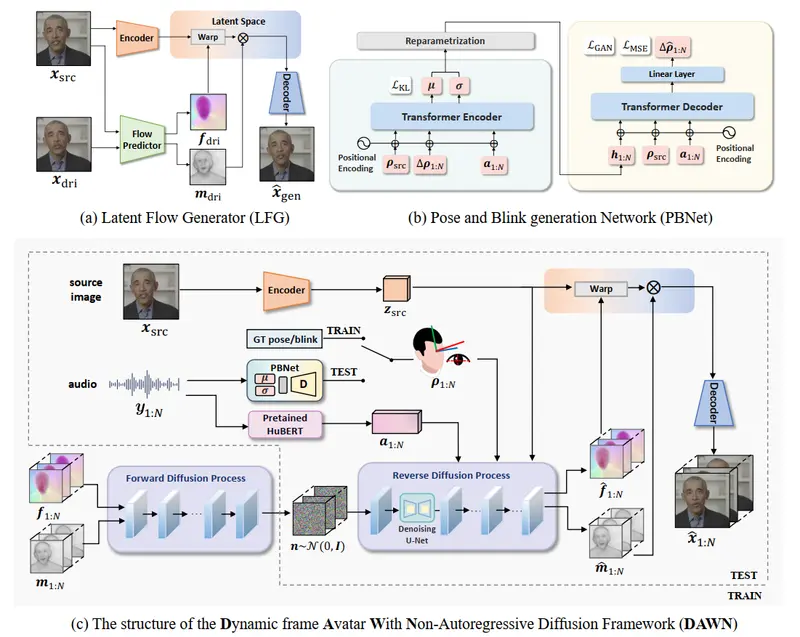
主要组件
DAWN 主要由两个组件构成:
- 潜在运动空间中的音频驱动整体面部动态生成:这一部分负责从音频信号中提取关键的面部运动信息,并将其映射到潜在运动空间中。通过这种方式,模型可以生成精确的唇部运动和其他面部表情变化。
- 音频驱动的头部姿势和眨眼生成:这一部分专注于生成自然的头部姿势和眨眼动作。通过结合音频信号,模型能够生成更加真实和自然的头部运动。
实验结果
广泛的实验表明,DAWN 在生成说话头视频方面表现出色,具有以下优势:
- 精确的唇部运动:DAWN 能够生成高度精确的唇部运动,确保语音和面部表情的同步性。
- 自然的姿势和眨眼动作:模型生成的头部姿势和眨眼动作自然流畅,增加了视频的真实感。
- 高生成速度:由于采用非自回归方法,DAWN 的生成速度显著快于现有的自回归方法。
- 稳定的长视频生成:DAWN 具有强大的外推能力,能够稳定生成高质量的长视频,避免了错误累积的问题。
具体应用场景:
- 虚拟会议:在远程工作中,使用DAWN可以生成参与者的头像视频,提高会议的互动性和真实感。
- 游戏和电影制作:在游戏或电影制作中,DAWN可以用来生成角色的头部动画,节省传统的动作捕捉和手动动画制作的时间和成本。
- 教育和培训:在教育领域,DAWN可以用于生成教学视频中的讲师头像,使学习材料更加生动有趣。
- 社交媒体:用户可以利用DAWN生成自己的动态头像视频,用于社交媒体平台,增加个人表达的多样性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











