
佐治亚理工学院和伊利诺伊大学厄巴纳-香槟分校的研究人员推出新型Transformer框架,它用于估计人在场景中注视的目标位置。这项技术的核心在于预测一个人在观看什么,这需要对个体的外观和场景内容进行推理。Gaze-LLE通过利用大规模预训练的特征提取器(如DINOv2),简化了以往复杂的注视目标估计流程,这些流程通常涉及多个分支的编码器和辅助模型来处理深度、姿态等信号。
- GitHub:https://github.com/fkryan/gazelle
- Gaze-LLE:https://huggingface.co/spaces/fffiloni/Gaze-LLE
- Gaze:https://huggingface.co/spaces/moondream/gaze-demo
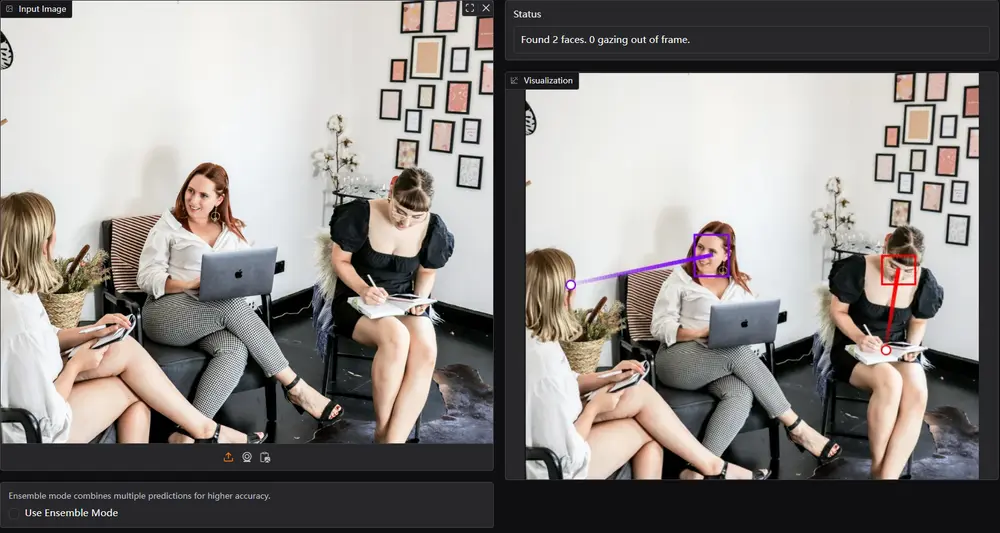
例如,在一个教室环境中,教师希望了解学生是否在关注教学内容。使用Gaze-LLE,可以通过分析学生头部的位置和场景中的教学材料,预测学生正在注视的具体位置,从而帮助教师调整教学策略,确保学生能够更好地吸收知识。
主要功能:
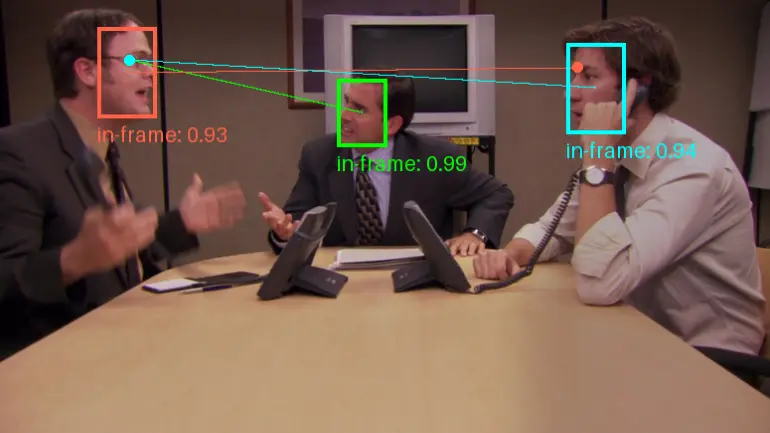
Gaze-LLE的主要功能是预测一个人在复杂场景中注视的具体位置,这涉及到从多模态信息中提取特征并进行融合,以实现高精度的注视目标估计。
主要特点:
- 简化架构:与传统的多分支方法相比,Gaze-LLE采用了一个更为简洁的架构,减少了模型参数的数量,降低了训练复杂度。
- 预训练特征利用:Gaze-LLE利用了预训练的视觉特征提取器(如DINOv2),这些提取器在大规模数据上进行了训练,能够提供强大的视觉特征。
- 头位置提示:Gaze-LLE通过引入头位置提示(head prompting)来解码个体的注视目标,而无需单独的头部分支。
- 实时性能:Gaze-LLE能够实现快速的注视目标估计,这对于实时应用场景非常有用。
工作原理:
Gaze-LLE的工作原理基于一个预训练的特征提取器(如DINOv2),它从输入的RGB图像中提取场景特征。然后,通过添加一个人特定的位置提示,使用一个轻量级的模块来解码注视目标。这个过程涉及到将场景特征和头位置信息结合起来,通过一个小型的可训练的变换器(transformer)模块来更新特征表示,最终预测出一个注视热图(heatmap)。
具体应用场景:
- 社交互动分析:在社交互动中,了解个体的注视目标可以帮助分析社交行为,例如自闭症评估中的共享注意力和相互注视。
- 人机交互:在人机交互系统中,通过估计用户的注视目标,可以提高交互的自然性和效率。
- 虚拟现实(VR)和增强现实(AR):在VR和AR应用中,Gaze-LLE可以用于更自然地控制视角和交互,提供更沉浸式的体验。
- 教育和培训:在教育和培训场景中,通过分析学生的注视行为,可以评估他们的注意力和学习效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











