苹果推出新预训练方法CLOC(对比定位语言-图像预训练),旨在提升图像和文本表示的预训练效果,特别是在局部区域的语义理解方面。CLOC模型可以生成高分辨率、细节丰富的深度图,这些深度图不仅包含整体图像的信息,还能够捕捉到图像中特定区域的细节。
CLOC通过补充CLIP以区域-文本对比损失和模块。苹果制定了一个新的概念,即可提示嵌入,其中编码器产生的图像嵌入在给定空间提示的情况下易于转换为区域表示。为了支持大规模预训练,苹果设计了一个视觉丰富且空间定位的描述框架,以有效地大规模生成区域-文本伪标签。通过扩展到数十亿张注释图像,CLOC能够为图像区域识别和检索任务提供高质量的 regional embeddings,并且可以作为CLIP的即插即用替代品,增强MLLMs,特别是在引用和定位任务上。
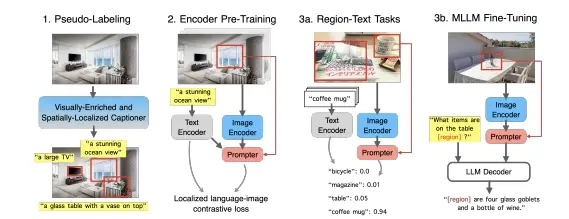
例如,你有一张包含多个物体的照片,比如一张包含人、树木和建筑物的风景照。CLOC模型能够分析这张照片,并为照片中的每个像素点以及特定区域(如树木或建筑物的一部分)计算出它的深度信息。这使得CLOC不仅能够理解整张照片的内容,还能够理解照片中特定区域的详细信息。
主要功能
CLOC的主要功能包括:
- 区域-文本对比损失:通过区域级别的文本对比,增强模型对图像特定区域的理解。
- Promptable Embeddings:模型能够生成易于转换为区域表示的图像嵌入,给定空间提示(如框选区域或文本提示)。
- 大规模伪标签数据引擎:为了支持CLOC训练,设计了一个能够生成区域-文本伪标签的框架。
主要特点
- 零样本区域级任务:CLOC能够在没有额外训练的情况下,直接用于区域级别的任务,如目标识别和区域文本检索。
- 高分辨率输出:CLOC能够生成高达2.25百万像素的深度图,提供丰富的细节。
- 快速生成:在标准GPU上,CLOC能够在0.3秒内生成一张深度图。
工作原理
CLOC的工作原理包含以下几个关键步骤:
- 多尺度视觉Transformer:CLOC使用多个尺度的视觉Transformer来捕捉全局图像上下文,同时关注局部细节。
- Prompter模块:CLOC引入了一个轻量级的Prompter模块,它可以根据空间提示(如框选区域)从图像嵌入中提取区域嵌入。
- 区域-文本对比损失:CLOC通过对比学习的方式,优化模型以生成与区域文本描述相匹配的区域嵌入。
- 大规模伪标签数据引擎:CLOC设计了一个数据引擎,通过视觉丰富的图像字幕生成器和开放词汇检测器,生成大规模的区域-文本注释。
具体应用场景
- 图像编辑:利用深度信息进行高级图像编辑,如背景虚化或3D效果。
- 虚拟现实和增强现实:在VR/AR应用中,通过深度信息模拟真实的视角变化和交互。
- 3D建模:使用深度图重建现实世界的三维模型。
- 多模态大型语言模型(MLLMs):CLOC可以作为MLLMs的视觉骨干网络,特别是在需要细粒度理解任务(如视觉问答)中。
总的来说,CLOC通过在预训练阶段引入区域级别的文本对比,增强了模型对图像局部区域的理解能力,从而在多种视觉-语言任务中展现出色的性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











