字节跳动推出一种新型视觉生成模型——随机自回归视觉生成(Randomized AutoRegressive Visual Generation,简称RAR)。该模型旨在通过自回归建模提高图像生成任务的性能,同时保持与语言模型框架的完全兼容性。例如,在图像生成领域,我们经常需要模型能够根据给定的条件生成高质量的图像。RAR模型就可以实现这一目标。假设我们想要生成一张具有特定风格或者内容的图片,RAR模型能够理解这些条件,并生成符合要求的图像。
- 项目主页:https://yucornetto.github.io/projects/rar.html
- GitHub:https://github.com/bytedance/1d-tokenizer
- Demo:https://huggingface.co/spaces/fun-research/TiTok
主要功能
RAR模型的主要功能是生成高质量的图像。它通过自回归的方式,一个接一个地预测图像中的每个像素或token,从而构建出整个图像。

主要特点
- 兼容性:RAR模型保持了与语言模型框架的兼容性,这意味着它可以利用现有的语言模型技术和优化策略。
- 随机排列:在训练过程中,输入序列会被随机排列,这有助于模型学习到所有可能的分解顺序,从而提高模型对双向上下文的建模能力。
- 渐进式随机性退火:通过逐渐减少随机排列的概率,模型最终会适应标准的光栅扫描顺序,这有助于提高图像生成的质量。
- 目标感知位置嵌入(Target-aware Positional Embedding):这是一种特殊的位置嵌入技术,它帮助模型在随机排列的训练过程中正确预测下一个token。
工作原理
RAR模型的工作原理基于自回归建模,它通过最大化所有可能的分解顺序上的预期似然来训练模型。在训练过程中,模型输入序列会以一定的概率随机排列,这个概率随着训练的进行而逐渐降低,直到最后完全按照光栅扫描顺序处理。这种随机排列的训练策略使得模型能够学习到图像数据的双向相关性,从而提高生成图像的质量。
具体应用场景
- 图像合成:在给定特定条件或风格的情况下生成新的图像。
- 数据增强:为机器学习模型提供额外的训练数据,通过生成图像来扩充数据集。
- 艺术创作:辅助艺术家或设计师探索新的视觉效果和风格。
- 游戏和娱乐:生成游戏中的环境、角色或物品的图像。
- 虚拟现实:创建虚拟环境中的图像内容。
RAR模型通过其创新的训练策略和保持与语言模型框架的兼容性,在图像生成领域展现了强大的潜力和广泛的应用前景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


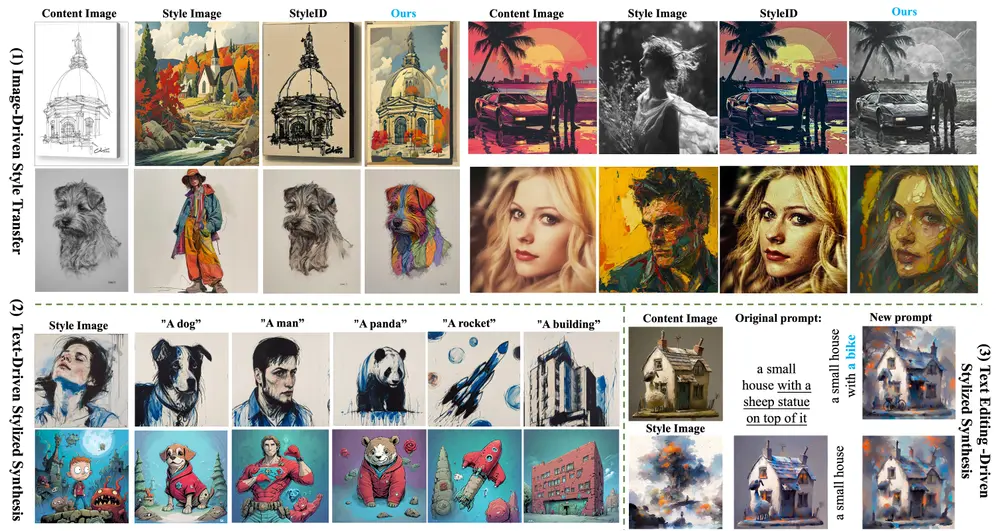

暂无评论...