
身份保持的文本到视频(IPT2V)生成旨在创建具有一致人类身份的高保真视频,这是视频生成领域的重要任务之一。然而,生成模型在这一方面仍然面临诸多挑战。北京大学、鹏城实验室、罗切斯特大学和新加坡国立大学的研究人员提出了ConsisID——一种基于扩散变压器(DiT)的无调优可控IPT2V模型,它在两个关键方向上推动了技术前沿:
- 无需繁琐的逐案例微调的无调优管道
- 频率感知的启发式身份保持控制方案
无调优管道的设计
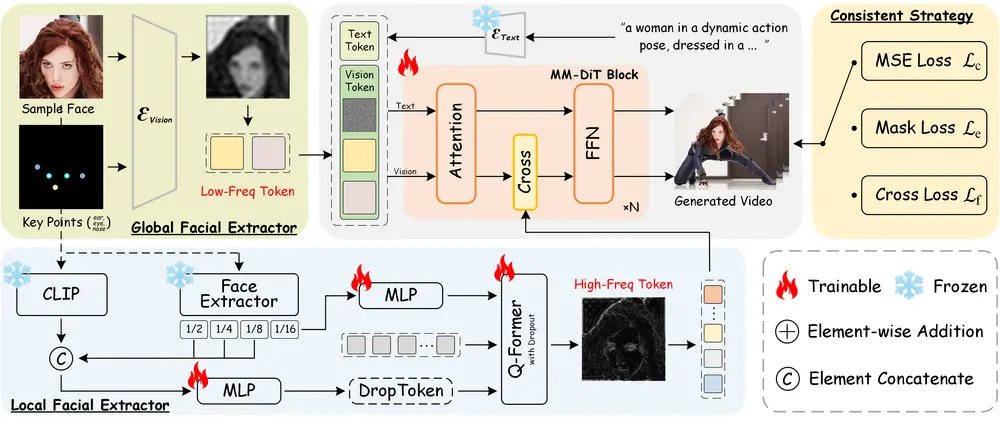
ConsisID的一个重要创新是其无调优管道设计。传统的方法通常需要为每个特定案例进行微调,这不仅耗时费力,还可能导致过拟合。ConsisID通过引入全局面部提取器和局部面部提取器,实现了无需额外微调即可保持一致的人类身份。
- 全局面部提取器:该模块将参考图像和面部关键点编码到潜在空间中,生成富含低频信息的特征。这些特征随后被整合到网络的浅层中,以缓解与扩散变压器(DiT)相关的训练挑战。
- 局部面部提取器:此模块专注于捕捉高频细节,并将其注入到变压器块中,增强模型保留细粒度特征的能力。这有助于确保生成视频中的人物身份在不同帧之间保持一致。
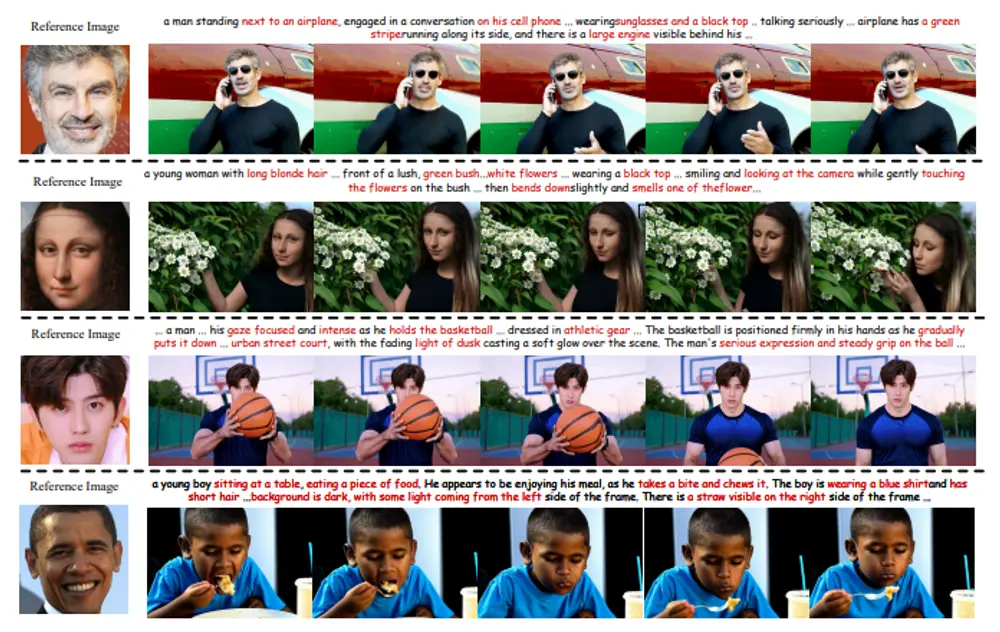
例如,你提供了一段描述:“一个穿着黑色上衣、戴着墨镜的男子站在飞机旁边,正在严肃地用手机通话。”同时,你还提供了一张特定人物的参考照片。ConsisID方法能够根据这段文本描述和参考照片生成一个视频,视频中的人物不仅会执行描述中的动作,而且其外观(如面部特征)将与参考照片中的人物保持高度一致。
- 项目主页:https://pku-yuangroup.github.io/ConsisID
- GitHub:https://github.com/PKU-YuanGroup/ConsisID
- 数据集:https://huggingface.co/datasets/BestWishYsh/ConsisID-preview-Data
- Demo:https://huggingface.co/spaces/BestWishYsh/ConsisID-preview-Space
频率感知的启发式控制方案
受视觉/扩散变压器频率分析的先前发现的启发,ConsisID采用了一种频率感知的启发式控制方案,将面部特征分解为低频全局特征和高频内在特征:
- 低频全局特征:例如,轮廓和比例等大尺度特征。这些特征通过全局面部提取器获取,并在生成过程中保持稳定,确保整体面部结构的一致性。
- 高频内在特征:如不受姿态变化影响的标识标记。局部面部提取器捕捉这些细节,使得生成的视频能够在细微之处也保持人物的身份特征。
为了更好地利用频率信息进行身份保持,研究人员提出了一种分层训练策略,将普通的预训练视频生成模型转变为IPT2V模型。这种策略不仅提高了训练效率,还增强了模型对复杂场景的适应能力。
实验验证
广泛的实验结果表明,ConsisID在生成高质量、身份保持的视频方面取得了优异的表现。具体来说:
- 一致性:生成的视频中,人物的身份在不同帧之间保持高度一致,无论是在静态图像还是动态变化的情况下。
- 保真度:视频的质量得到了显著提升,细节丰富且自然,接近真实世界的视觉效果。
- 鲁棒性:ConsisID对不同的输入条件表现出色,包括不同的文本提示和参考图像,展示了其广泛的应用潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











