
阿里巴巴推出创新框架EMO,它是一个能够根据音频生成表情丰富的肖像视频的系统。想象一下,你只需要提供一张静态的照片和一段语音,EMO就能创造出一个视频,视频中的人物头像会根据语音的内容和情感变化做出相应的表情和头部动作,就像真人在说话或唱歌一样。
此框架支持多语言、谈话、唱歌以及快语速的适配,可以根据输入视频的长度生成任意持续时间的视频。

主要功能:
- 生成与输入音频同步的动态视频,包括说话和唱歌。
- 保持视频中人物表情的真实性和自然性。
- 支持任意长度的视频生成,取决于输入音频的长度。
主要特点:
- 无需3D模型或面部标记: EMO直接从音频到视频的合成方法,省去了复杂的中间步骤。
- 高表达性和真实感: 通过实验结果,EMO在表达性和真实感方面显著优于现有的技术。
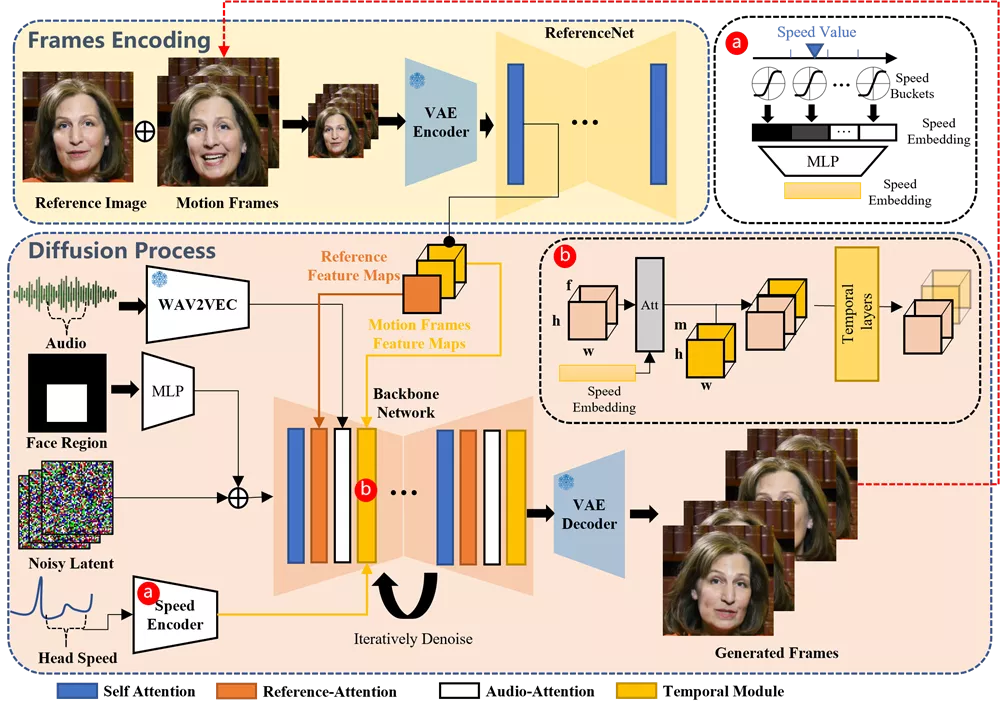
- 稳定性和一致性: 通过速度控制器和面部区域控制器,确保视频帧之间的平稳过渡和人物身份的一致性。
工作原理:
- 音频处理: 使用预训练的音频编码器处理输入的音频,提取音频特征。
- 面部区域控制: 使用面部定位器和速度层来控制人物面部的生成位置和运动速度。
- 视频生成: 利用稳定的扩散模型(Stable Diffusion)作为基础框架,通过去噪过程将噪声从潜在的视频中去除,同时结合音频特征和参考图像特征,生成连贯的视频帧。
- 时间模块: 通过自注意力时间层来处理视频帧之间的时间关系,确保视频的连贯性。
应用场景:
- 虚拟助手: 在智能设备上,EMO可以用来生成虚拟助手的视频,使其看起来更加生动和互动。
- 娱乐和社交媒体: 用户可以上传自己的照片和音频,生成个性化的动态表情视频,用于社交媒体分享。
总的来说,EMO通过结合先进的扩散模型和音频处理技术,为用户带来了一种全新的、能够生成高度个性化和富有表现力的动态视频肖像的方法。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











